Rows: 1599 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (12): fixed acidity, volatile acidity, citric acid, residual sugar, chlo...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
## Revisar la estructura de los datosstr(wine_raw)
Los datos corresponden a una variación de un vino tradicional portugués llamado “Vinho Verde” proveniente de una región llamada Vinho, ubicada muy al norte de Portugal.
Variables
fixed acidity: ácidos del vino que no se evaporan fácilmente.
volatile acidity: cantidad de ácido acético en el vino, el cual en altas cantidades genera sensaciones no placenteras y un sabor vinagroso.
citric acid: cantidad de ácido cítrico en pequeñas cantidades, el cual añade cierta frescura y sabor al vino.
residual sugar: cantidad de azucar residual luego del proceso de fermentación. Es raro tener menos de 1g/litro y los vinos con más de 45g/litro se consideran dulces.
chlorides: cantidad de sal en el vino.
free sulfur dioxide: cantidad de dióxido de azufre (S02) libre, el cual previene el crecimiento de microbios y la oxidación del vino.
total sulfur dioxide: cantidad total de dióxido de azufre (S02) en forma libre y fija; en bajas concentraciones es indetectable, en concentraciones superiores a 50ppm el SO2 es evidente para la nariz y el sabor del vino.
density: la densidad del vino es cercana a la del agua dependiendo de la cantidad de azucar y alcohol.
pH: describe qué tan ácido o básico es un vino en un escala desde cero (muy ácido) hasta 14 (muy básico); la gran mayoría de vinos tienen un pH entre 3-4.
sulphates: un aditivo que contribuye a regular los niveles de dióxido de azufre (S02), el cual actúa como antimicrobios y antioxidante.
alcohol: porcentaje del alcohol del vino.
quality: puntuación del vino basada en datos sensoriales, en una escala entre 0 y 10.
Fuente
Cortez, P., Cerdeira, A., Almeida, F., Matos, T., & Reis, J. (2009). Modeling wine preferences by data mining from physicochemical properties. Decision Support Systems, 47(4), 547-553.
Note que es muy importante tener un contexto sobre el conjunto de datos.
Dimensionalidad de los datos
dim(wine_raw)
[1] 1599 12
1599 individuos - Número de filas
12 variables - Número de columnas
Todos los cálculos y procedimientos matemáticos y estadísticos, a nivel computacional, se realizan mediante operaciones sobre las estructuras de datos vistas en la práctica de programación básica.
## Obtener solo el número de filasnrow(wine_raw)
[1] 1599
## Obtener solo el número de columnasncol(wine_raw)
[1] 12
Limpieza de los datos
En la práctica la calidad de los datos puede estar afectada por los procesos de captura, sistematización y distribución. Siempre hay que verificar la calidad de nuestros datos.
Limpieza de tablas (3 principios vistos en clase)
Nombrado adecuado de las variables
Datos faltantes
Datos atípicos
Valores duplicados
Para mayor detalle, consulte el material de la practica de limpieza de datos.
En este caso la base de datos proporcionada ya tiene una estructura adecuada para el procesamiento, salvo que los nombres de las columnas tienen espacios y no siguen las convenciones del naming de variavbles, por lo que vamos a ponerles un buen nombre
Dado que inicialmente todas las variables son cuantitativas, vamos a realizar una operación sobre nuestro conjunto de datos para agregar dos nuevas columnas categóricas, de tal manera que podemos explorar algunas medidas y gráficas relevantes.
## Partimos de la base de datos 'wine_raw'## y la ontroducimos a un algoritmo de operacioneswine_raw %>%## mutate() crea una nueva variable llamada 'calidad'## basada en los rangos ya conocidos de la variable qualitymutate(calidad =ifelse( quality =='3'| quality =='4','baja',ifelse( quality =='5'| quality =='6','media','alta')) ) %>%## mutate_at() recibe la columna 'calidad' y la convierte en un factormutate_at('calidad', factor) %>%## mutate() crea una nueva variable llamada 'acetico'## basada en rangos conocidos de la variable 'volatile_acidity'mutate(acetico =ifelse(volatile_acidity <0.7, 'bajo', 'alto') ) %>%## mutate_at() recibe la columna 'acetico' y la convierte en un factor## el resultado de todas las operaciones se guarda en 'wine_processed'mutate_at('acetico', factor) -> wine_processed# Especificamos el orden de los factores que acabamos de crearwine_processed$calidad <-factor(wine_processed$calidad, levels =c("baja","media","alta"))wine_processed$acetico <-factor(wine_processed$acetico, levels =c("bajo","alto"))
Análisis descriptivo
Resumen numérico
El método summary() que trae por defecto R nos brinda estadísticas de resumen para cada una de las variables de nuestro conjunto de datos.
## Resumen básico de datossummary(wine_processed)
fixed_acidity volatile_acidity citric_acid residual_sugar
Min. : 4.60 Min. :0.1200 Min. :0.000 Min. : 0.900
1st Qu.: 7.10 1st Qu.:0.3900 1st Qu.:0.090 1st Qu.: 1.900
Median : 7.90 Median :0.5200 Median :0.260 Median : 2.200
Mean : 8.32 Mean :0.5278 Mean :0.271 Mean : 2.539
3rd Qu.: 9.20 3rd Qu.:0.6400 3rd Qu.:0.420 3rd Qu.: 2.600
Max. :15.90 Max. :1.5800 Max. :1.000 Max. :15.500
chlorides free_sulfur_dioxide total_sulfur_dioxide density
Min. :0.01200 Min. : 1.00 Min. : 6.00 Min. :0.9901
1st Qu.:0.07000 1st Qu.: 7.00 1st Qu.: 22.00 1st Qu.:0.9956
Median :0.07900 Median :14.00 Median : 38.00 Median :0.9968
Mean :0.08747 Mean :15.87 Mean : 46.47 Mean :0.9967
3rd Qu.:0.09000 3rd Qu.:21.00 3rd Qu.: 62.00 3rd Qu.:0.9978
Max. :0.61100 Max. :72.00 Max. :289.00 Max. :1.0037
pH sulphates alcohol quality calidad
Min. :2.740 Min. :0.3300 Min. : 8.40 Min. :3.000 baja : 63
1st Qu.:3.210 1st Qu.:0.5500 1st Qu.: 9.50 1st Qu.:5.000 media:1319
Median :3.310 Median :0.6200 Median :10.20 Median :6.000 alta : 217
Mean :3.311 Mean :0.6581 Mean :10.42 Mean :5.636
3rd Qu.:3.400 3rd Qu.:0.7300 3rd Qu.:11.10 3rd Qu.:6.000
Max. :4.010 Max. :2.0000 Max. :14.90 Max. :8.000
acetico
bajo:1366
alto: 233
Resumen gráfico
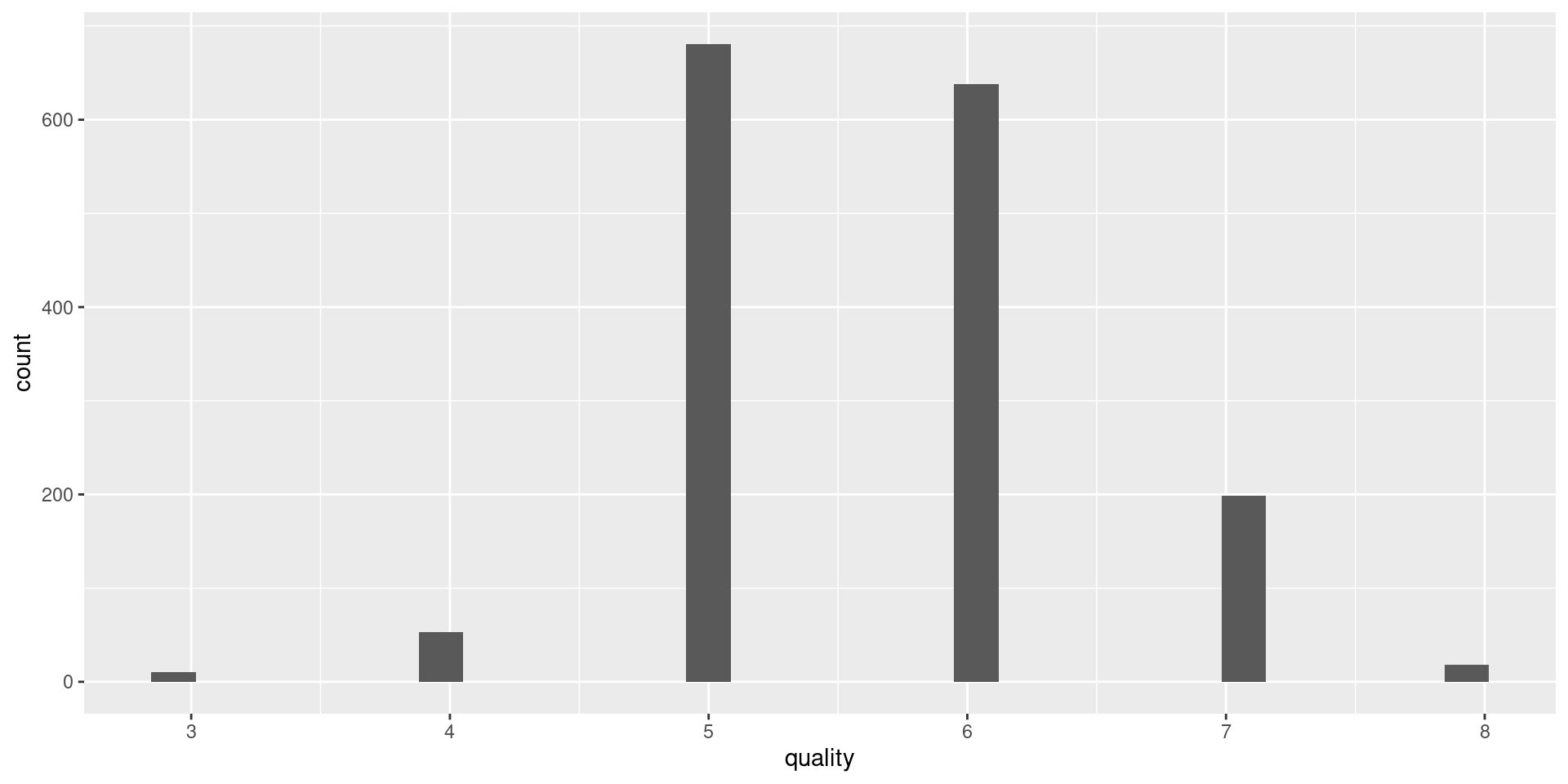
## Cargamos la librería ggplot2library("ggplot2")## Usamos el método para graficar histogramas## Seleccionamos como objetivo la variable qualityggplot(wine_processed, aes(quality)) +geom_histogram()
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Note que podemos hacer histogramas para las demás variables. Además, podríamos realizar otros tipos de gráficos univariados.
Nuestro interés ahora será construir resúmenes numéricos y resúmenes gráficos entre dos o más variables.
Efectos de una variable sobre otra
En una investigación o estudio podemos sospechar de la influencia o efecto de un conjunto de variables sobre una variable particular de interés (target / label / variable crítica / variable explicada). Una parte esencial de la fase de análisis es reunir evidencia para seleccionar las variables que tengan mayor probabilidad de tener un efecto sobre nuestra variable de interés.
Existen distintas herramientas estadísticas para tener una idea bien formada de cómo se relacionan dos o más variables entre sí.
Antes de explorar dichas herramientas, conviene hacer una revisión sobre algunos conceptos.
Asociación entre dos variables contínuas
La covarianza es una medida numérica que nos permite cuantificar la relación (lineal) entre dos variables contínuas.
Visualización de la relación entre variables
Hemos visto que podemos crear gráficos univariados para tener una fotografía del comportamiento de una variable. De igual manera, es posible construir gráficos que muestren la asociación entre dos o más variables.
Variable 1
Variable 2
Visualización frecuente
Categórica
Categórica
Tablas de contingencia
Categórica
Contínua
Boxplot por grupos
Contínua
Contínua
Diagrama de dispersión
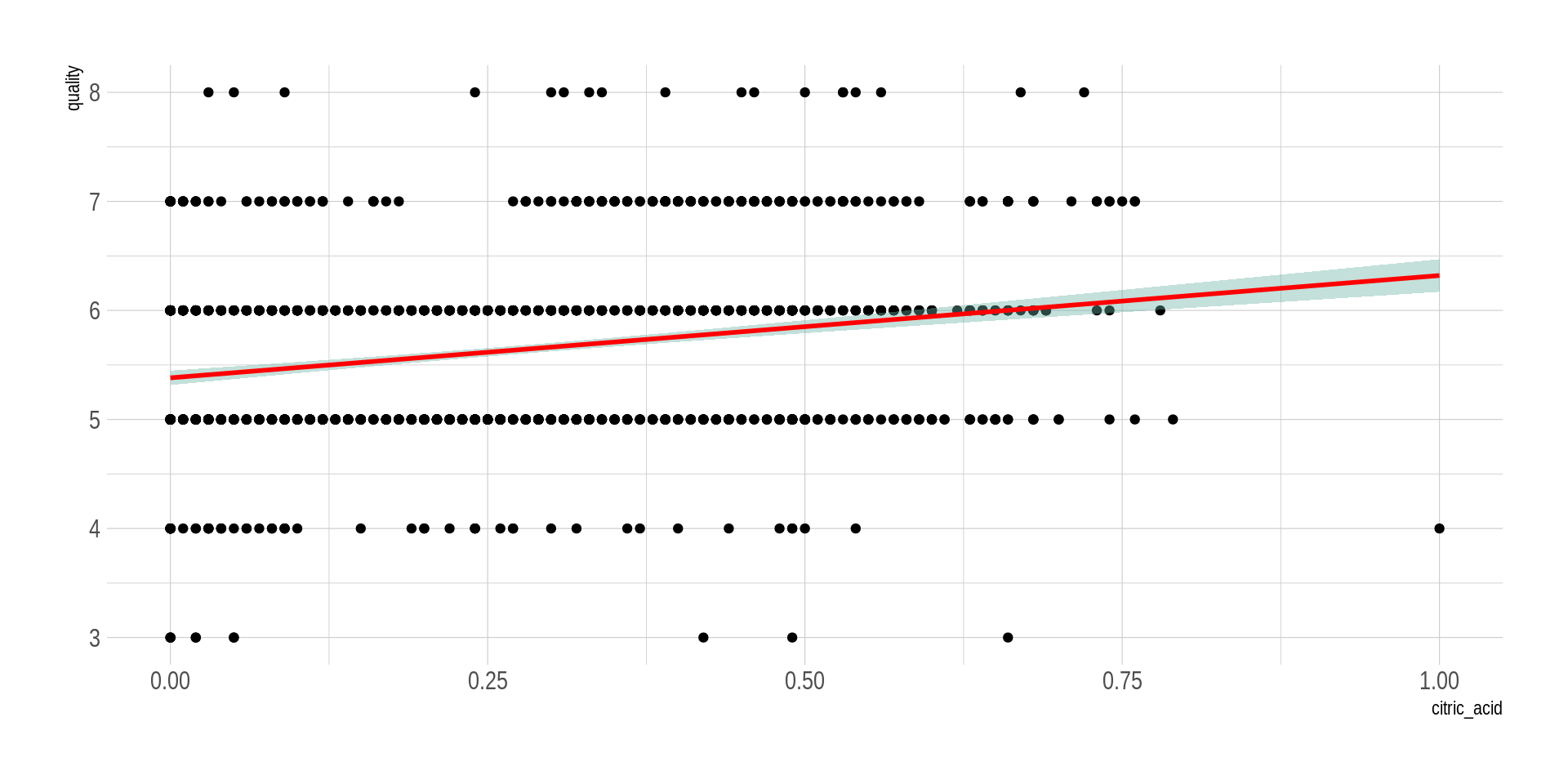
Para nuestro ejemplo del vino rojo, siguiendo las recomendaciones de la tabla, conviene crear diagramas de dispersión.
Diagrama de dispersión
Son útiles porque al cruzar los valores de un par de variables podemos encontrar posibles relaciones matemáticas entre ellas.
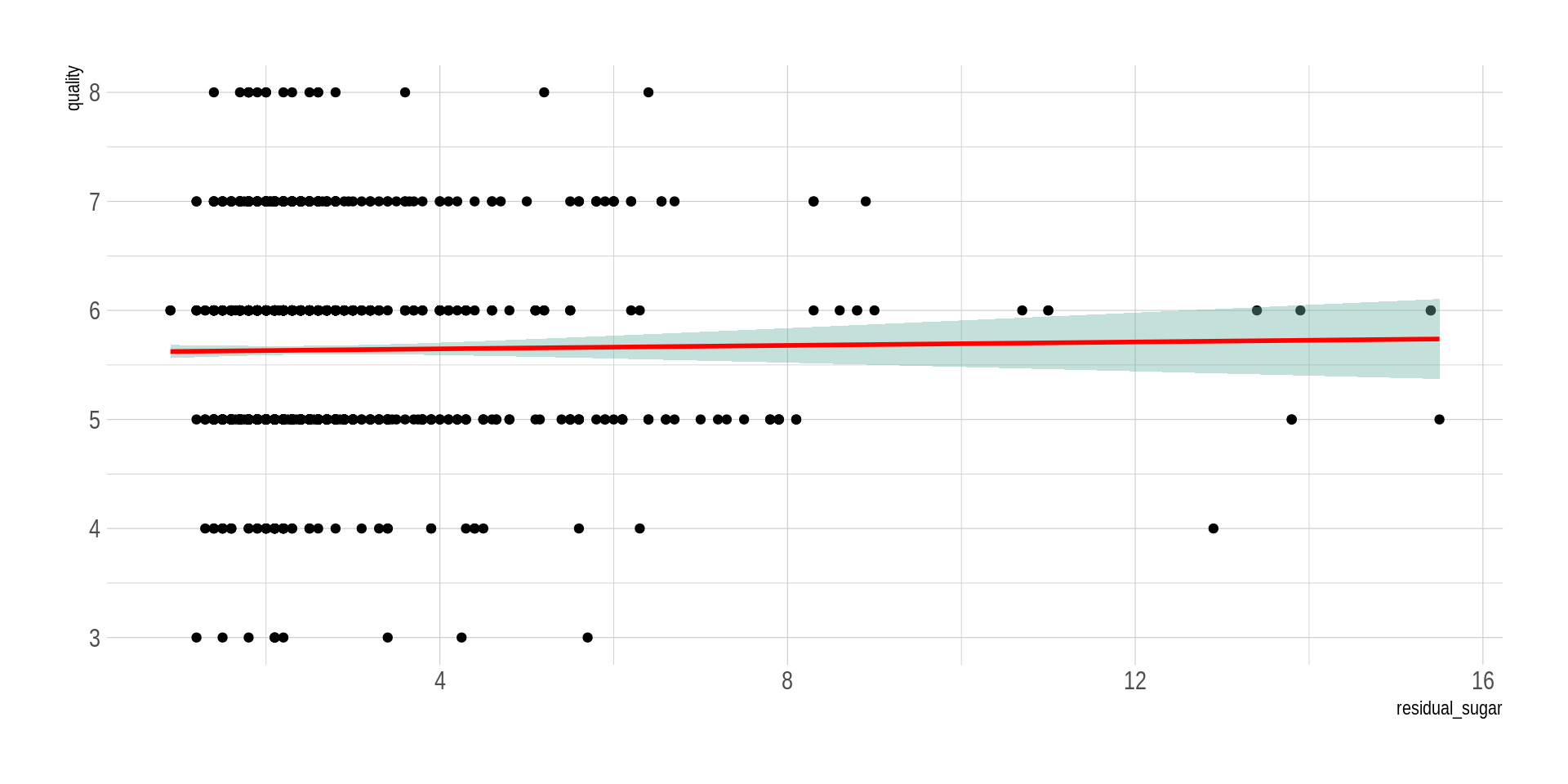
# install.packages("hrbrthemes")library("hrbrthemes")## Una relación lineal inexistenteggplot(wine_processed, aes(x=residual_sugar, y=quality)) +geom_point() +geom_smooth(method=lm , color="red", fill="#69b3a2", se=TRUE) +theme_ipsum()
`geom_smooth()` using formula = 'y ~ x'
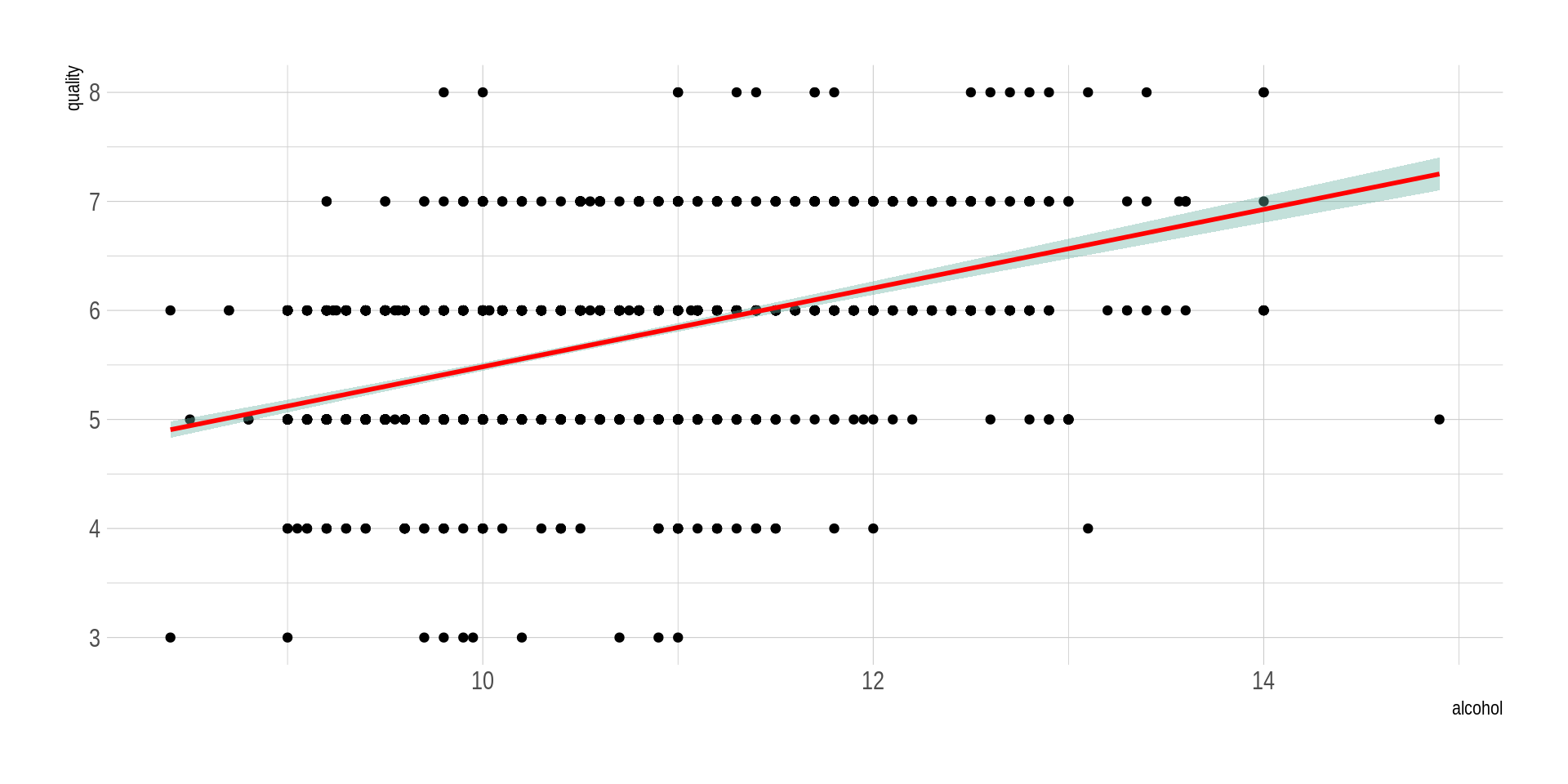
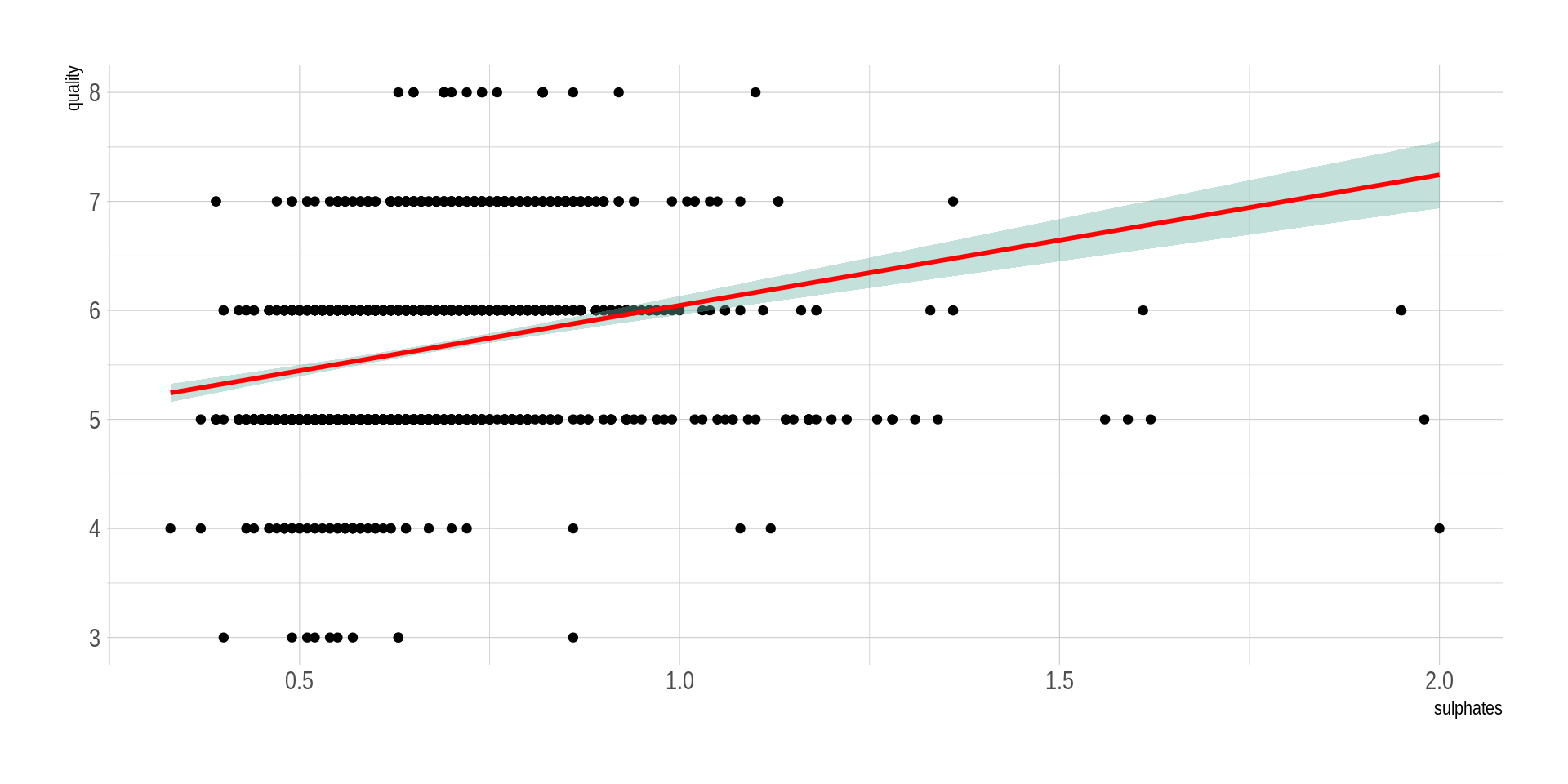
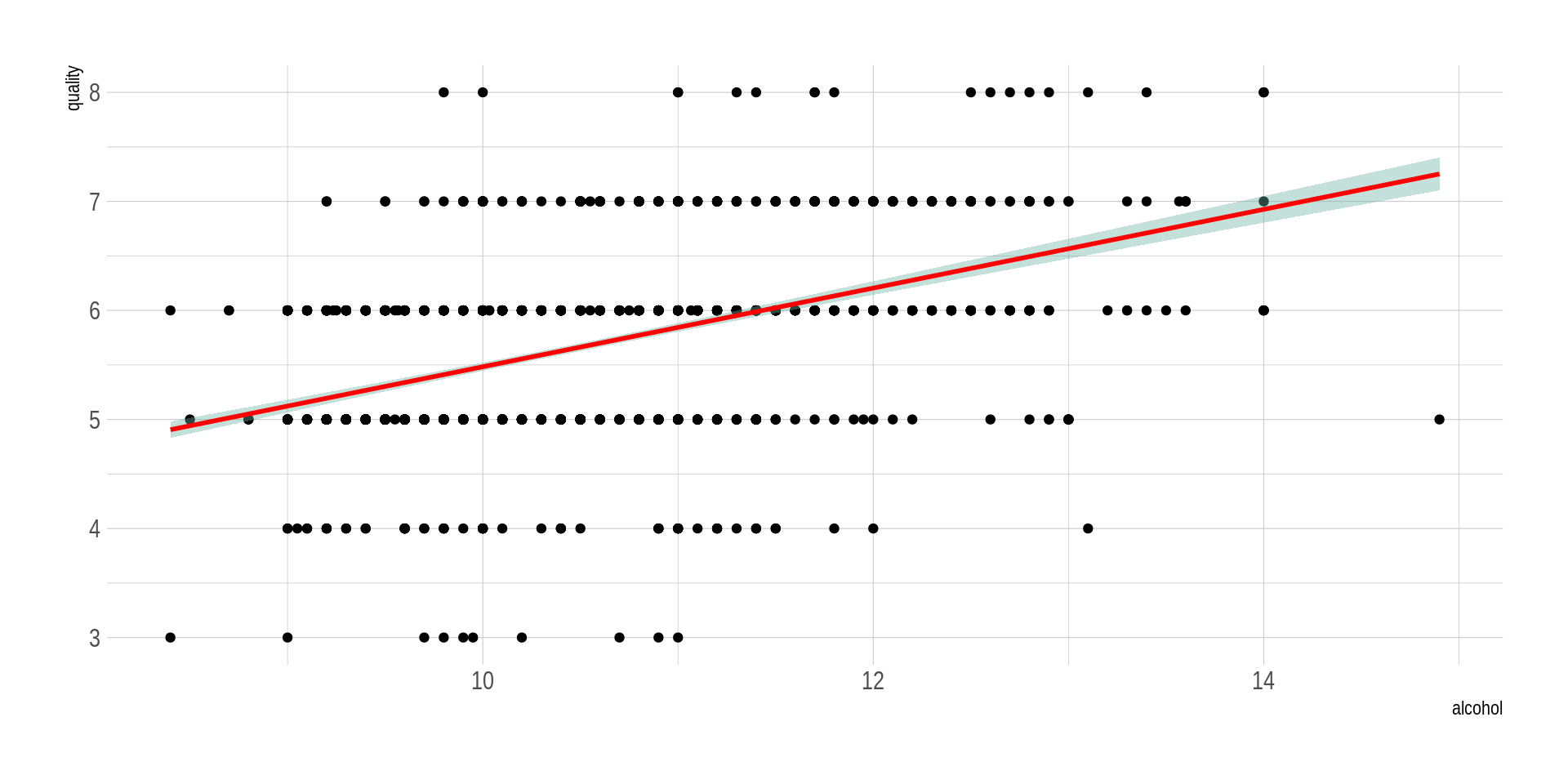
## Una relación lineal positivaggplot(wine_processed, aes(x=alcohol, y=quality)) +geom_point() +geom_smooth(method=lm , color="red", fill="#69b3a2", se=TRUE) +theme_ipsum()
`geom_smooth()` using formula = 'y ~ x'
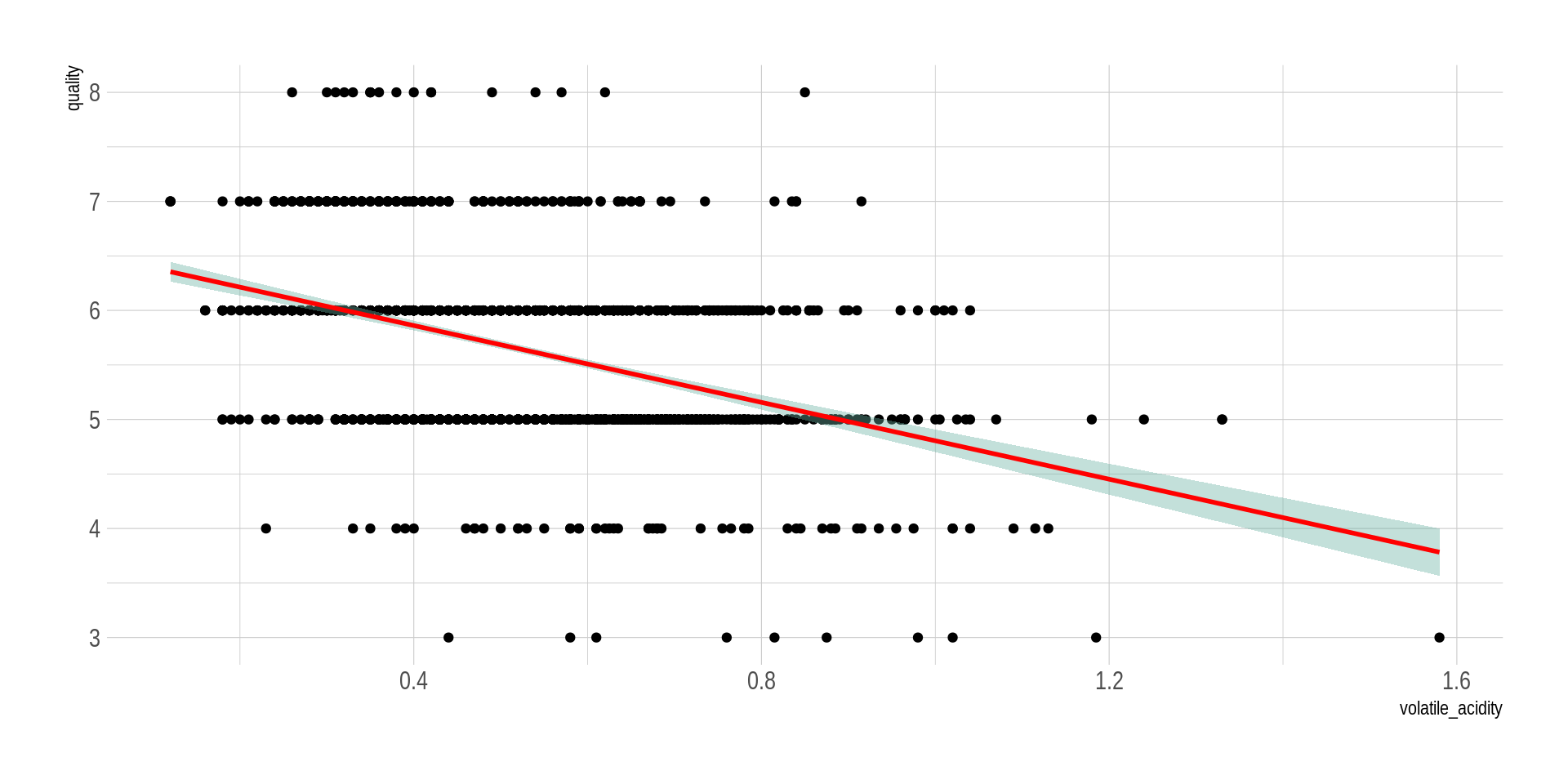
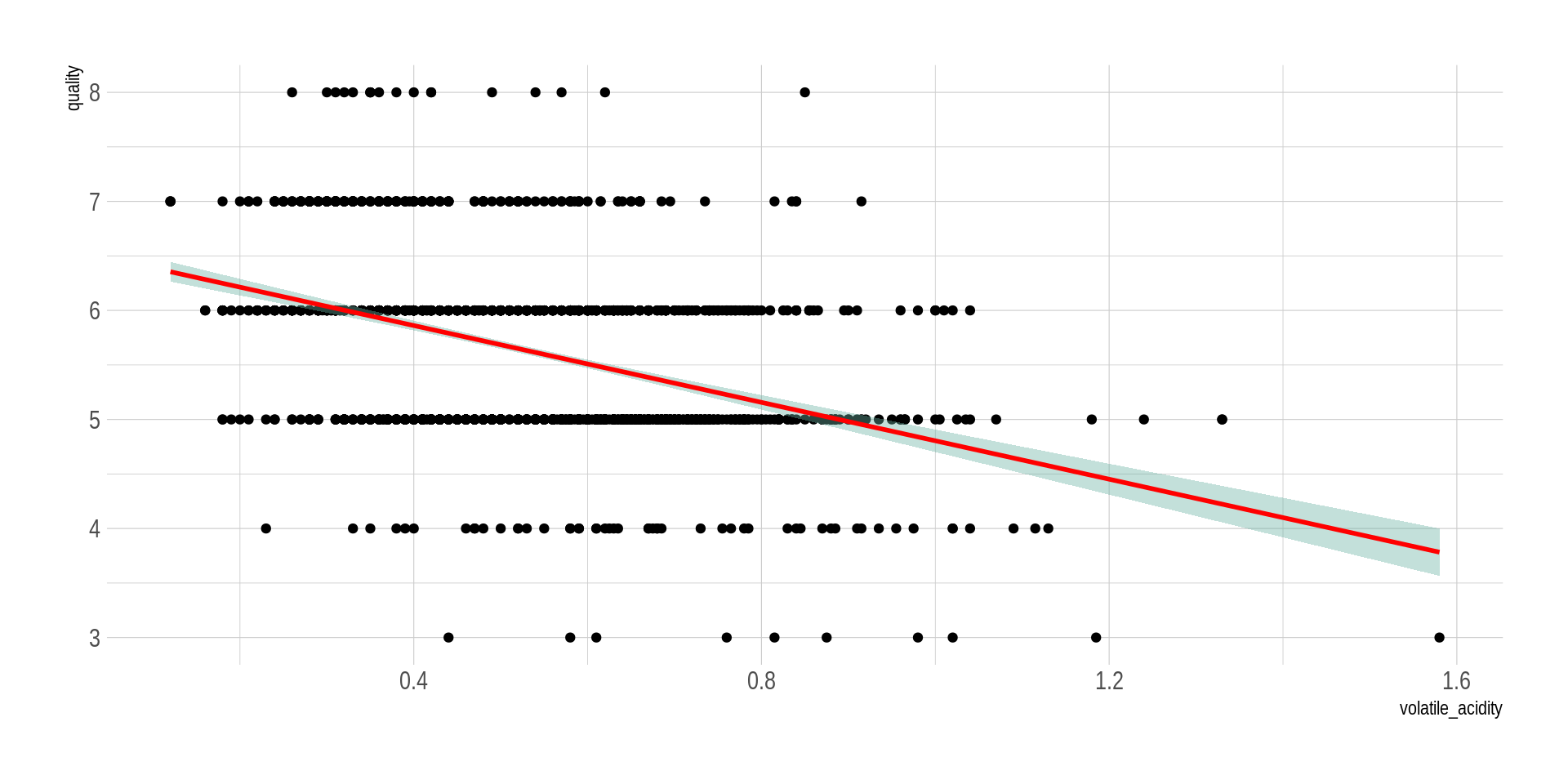
## Una relación lineal negativaggplot(wine_processed, aes(x=volatile_acidity, y=quality)) +geom_point() +geom_smooth(method=lm , color="red", fill="#69b3a2", se=TRUE) +theme_ipsum()
`geom_smooth()` using formula = 'y ~ x'
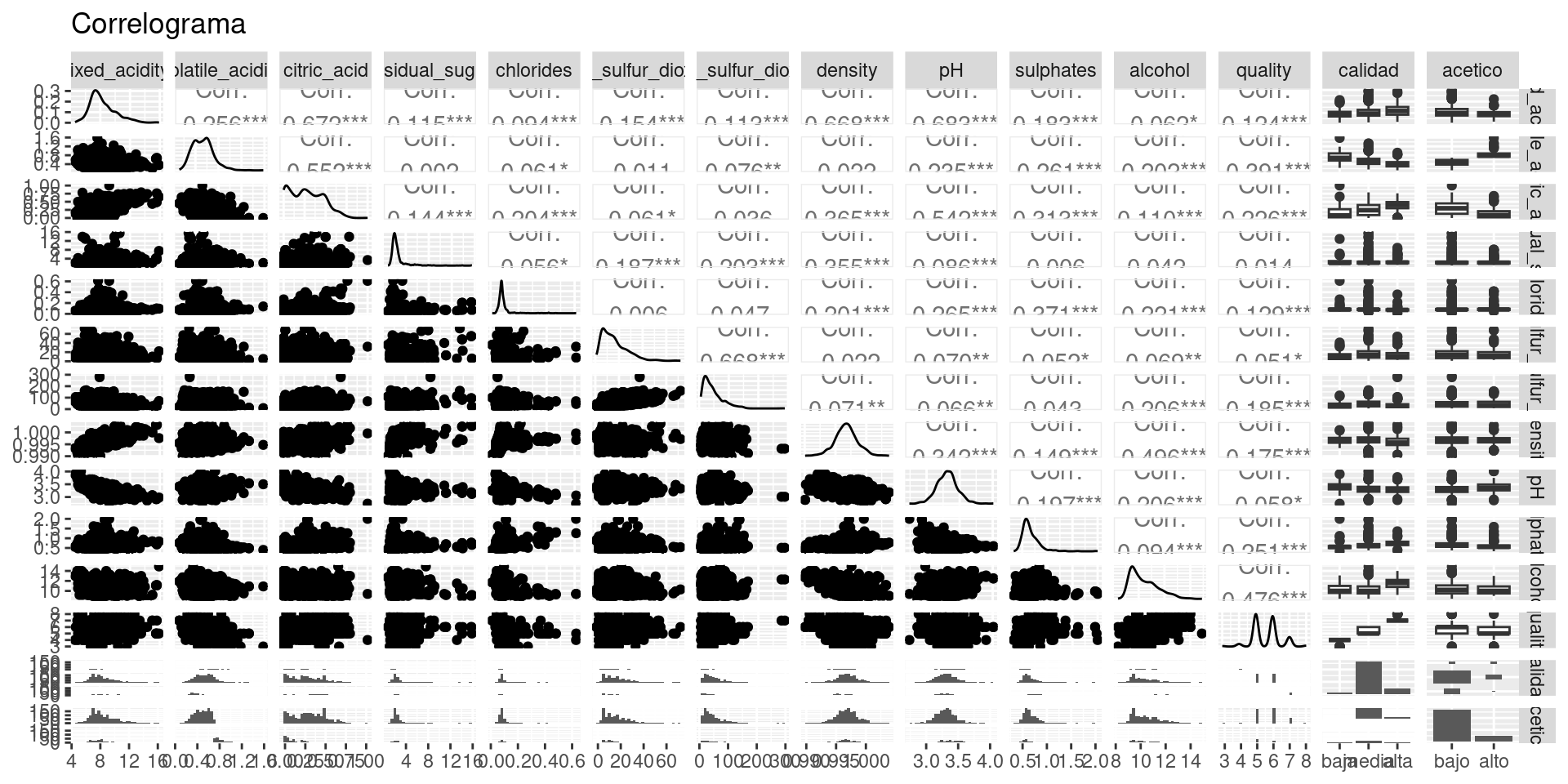
Correlogramas
Podemos crear una visualización donde se muestren todos los posibles diagramas de dispersión entre parejas de variables con sus respectivos coeficientes de correlación.
## Instalamos la librería GGallyinstall.packages('GGally')
## Cargamos la libreríalibrary('GGally')
Registered S3 method overwritten by 'GGally':
method from
+.gg ggplot2
## Creamos la visualización usando el método ggpairs()ggpairs( wine_processed, title="Correlograma" )
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
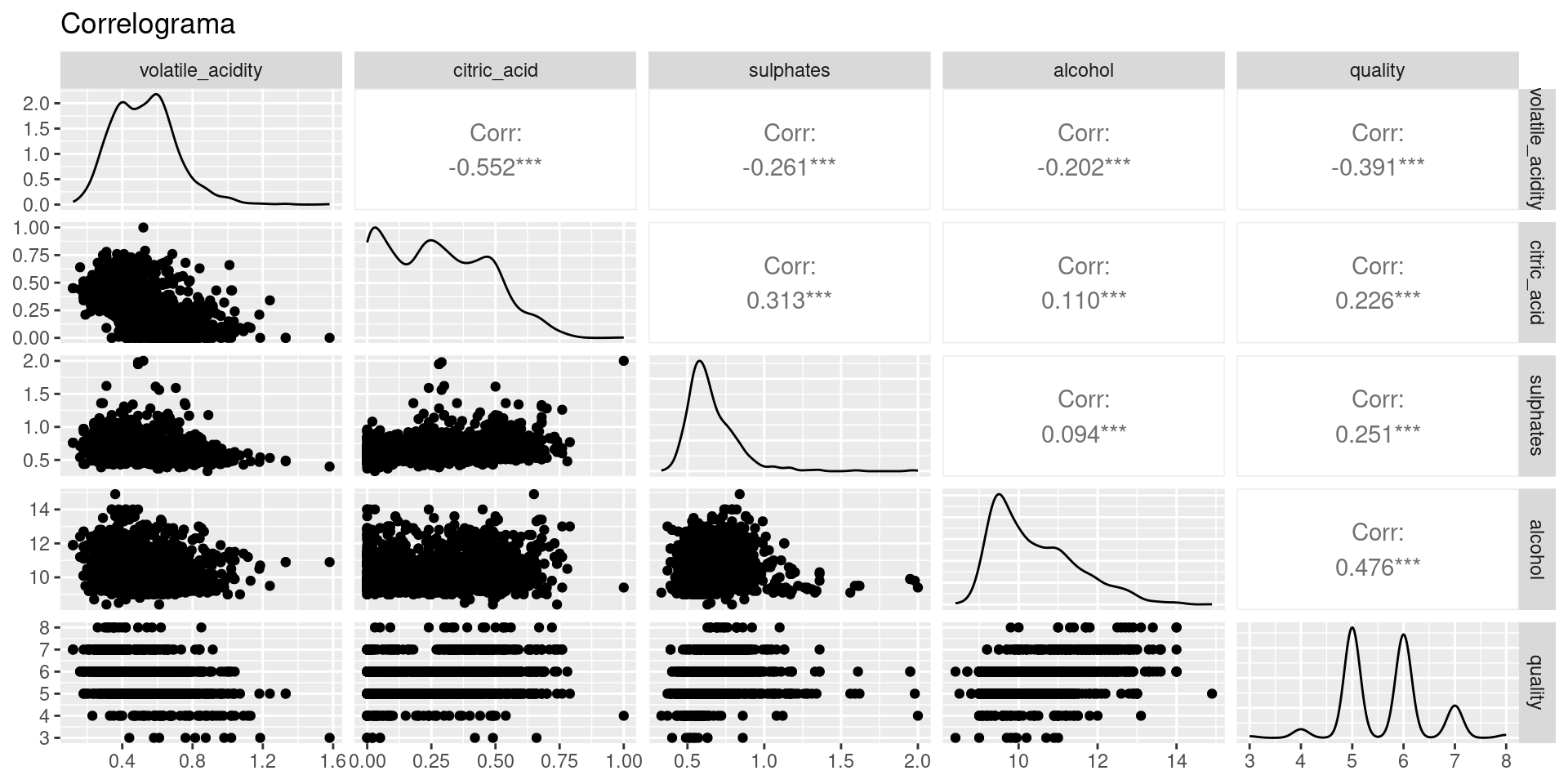
Podemos graficar filtrando ciertas variables de interés. En este caso, vamos a remover aquellas que tengan un coeficiente de correlación menor a 0.2 con nuestra variable target (quality).
## Declaramos un vector con nuestras variables de interésvar_interes =c('volatile_acidity','citric_acid','sulphates','alcohol','quality')## Creamos la visualización usando el método ggpairs() agregando el parámetro columnsggpairs( wine_processed, title="Correlograma",columns = var_interes )
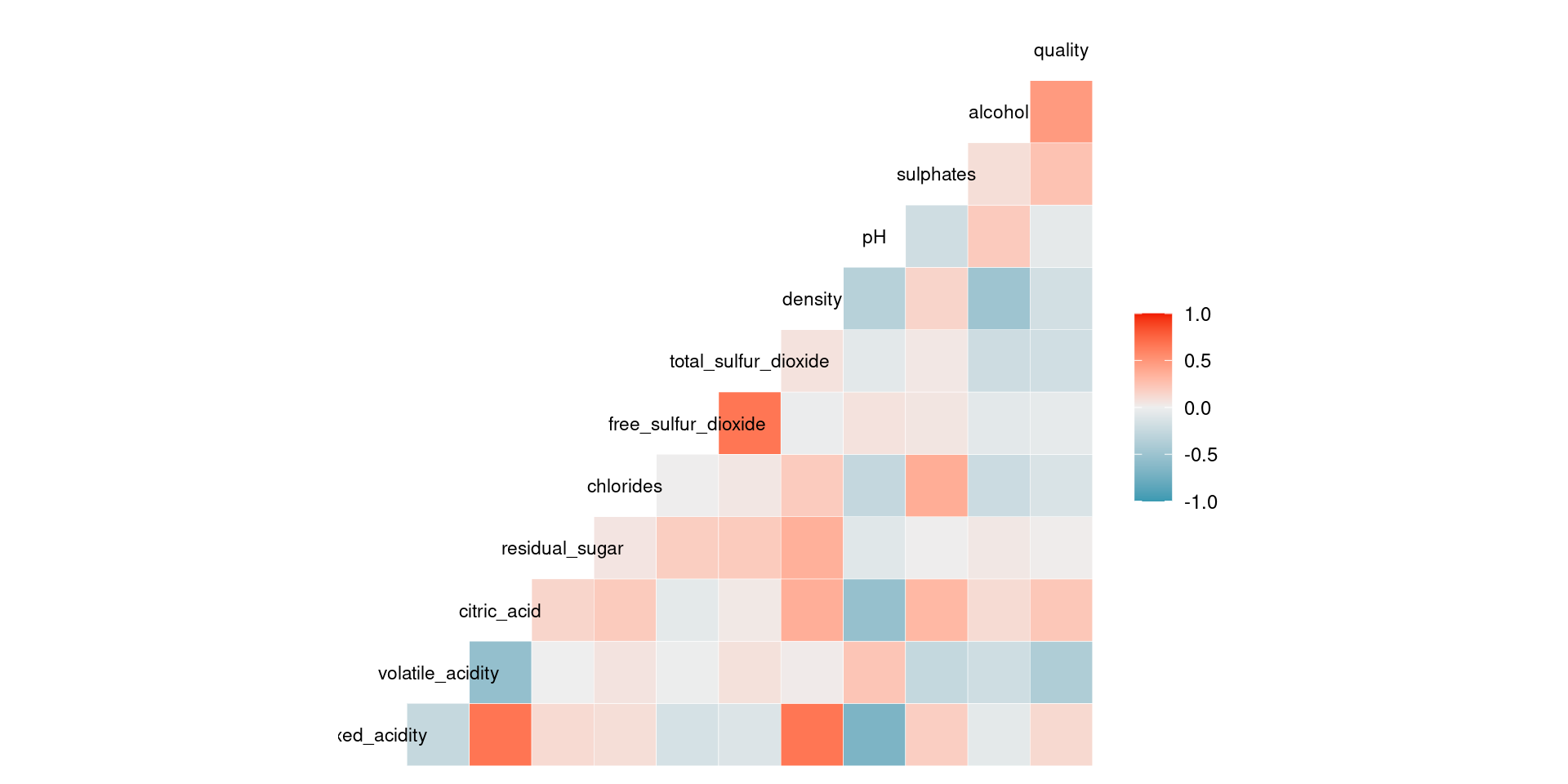
Otra forma de visualizar la correlación entre variables.
De las anteriores matrices y gráficas podemos observar algunas nuevas correlaciones de interés, por ejemplo, entre el pH y la acidéz. Podemos observar además que para la variable target aproximadamente la mitad de las variables independientes correlacionan positivamente y la otra mitad negativamente.
En la práctica, se pueden seleccionar las variables independientes que tienen las medidas de asociación más altas en la medida que sospechamos que nos aportan más información. Una regla de oro sencilla es excluir variables que tengan una correlación menor (en valor absoluto) a 0.2.
Examen detallado de variables de interés
De nuestro conjunto de datos iniciales hemos detectado ciertas variables independientes o explicativas que nos pueden aportar mayor información para explicar la calidad del vino.
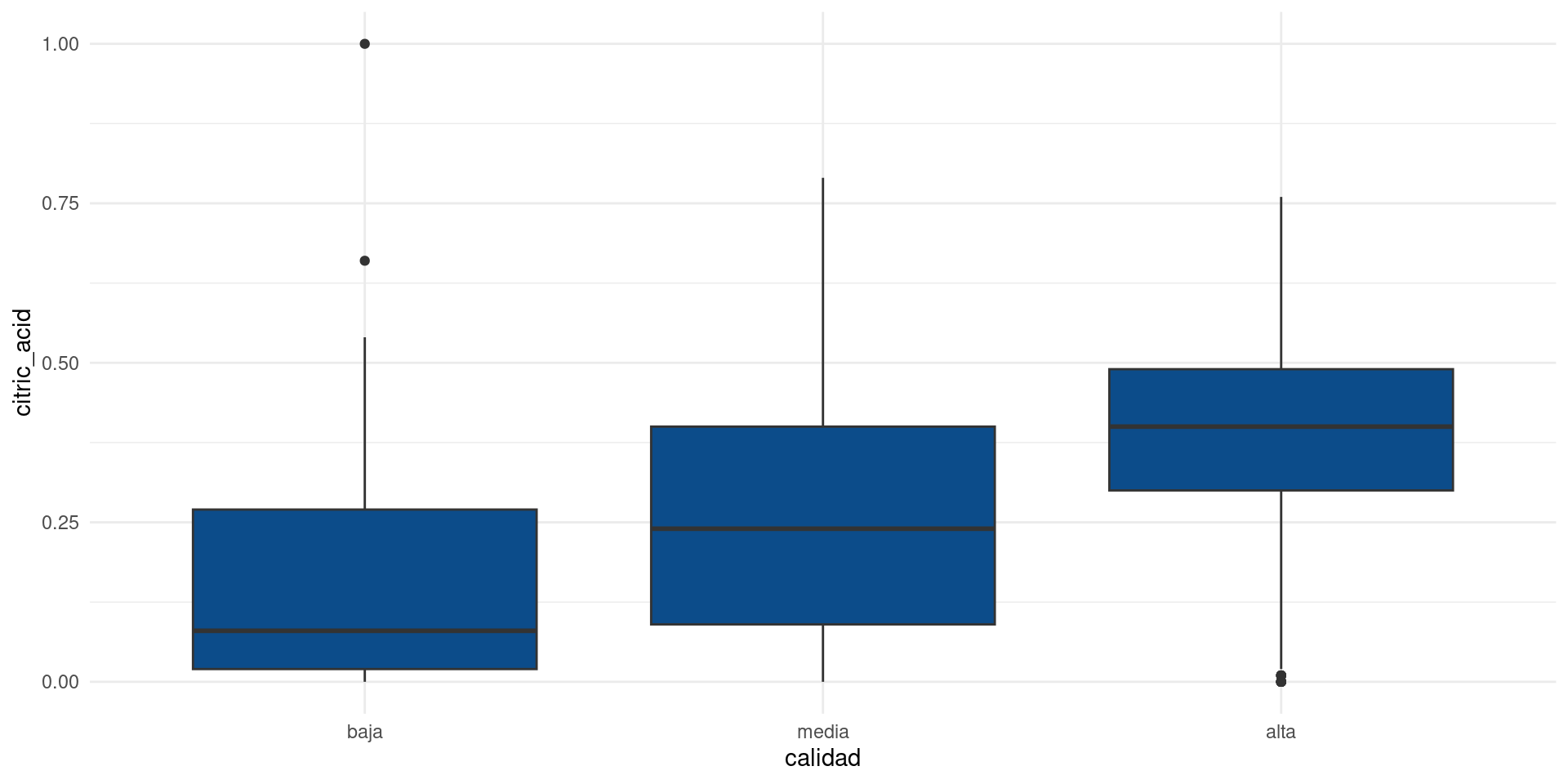
volatile_acidity
citric_acid
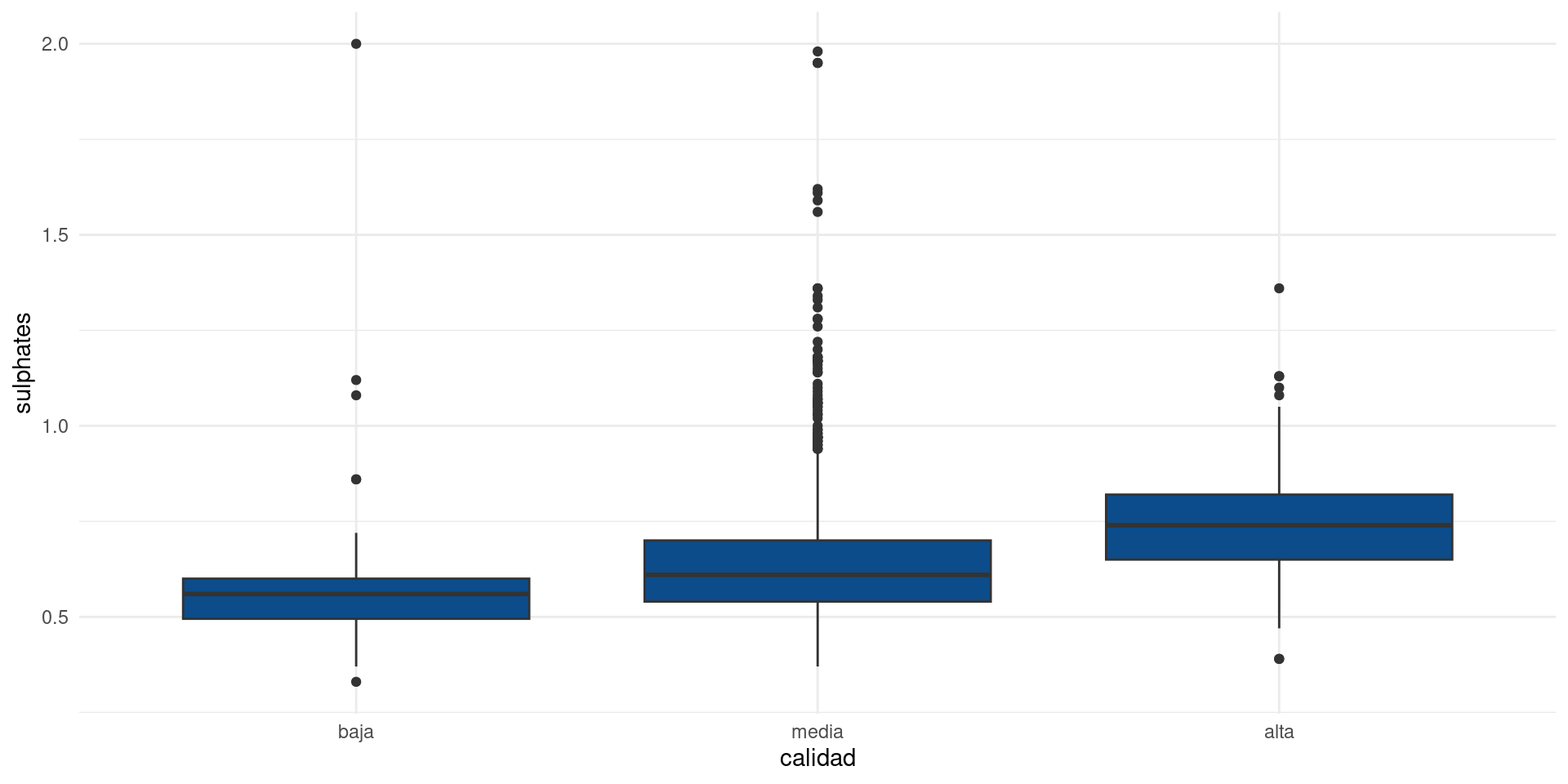
sulphates
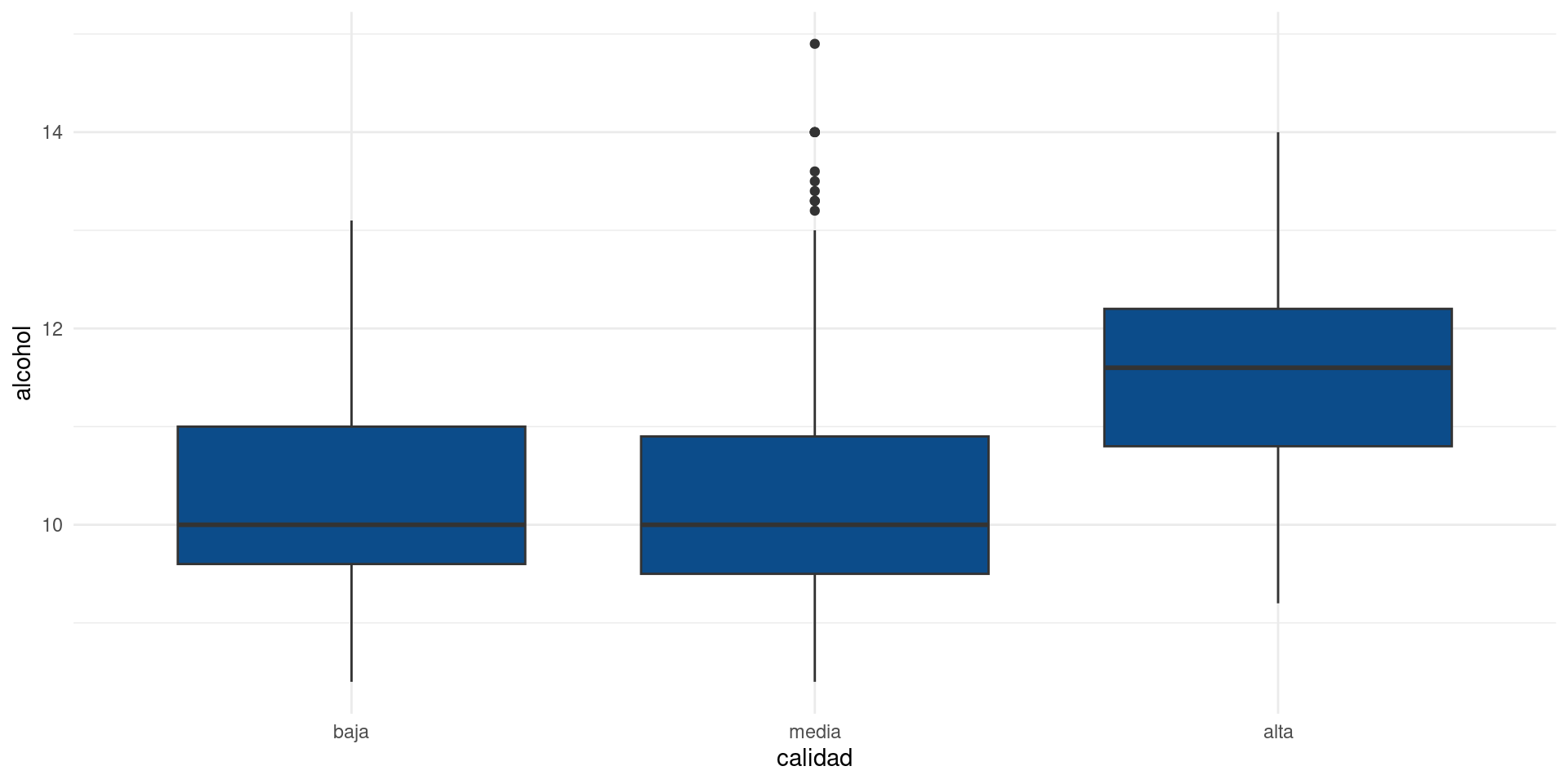
alcohol
Adicionalmente, tenemos la calidad del vino expresada como una variable contínua (quality) y también de forma categórica (calidad).
¿Qué deberíamos hacer? Analizar el comportamiento conjunto de cada una de nuestras variables explicativas con la variable crítica. Dicho esto, vamos ahora a realizar estos cruces bivariados en tres escenarios:
Escenario 1: Asociación entre dos variables contínuas
Ya vimos cómo hacer el cálculo de coeficientes de correlación. Examinemos ahora en diagramas de dispersión las relaciones entre las variables de interés y la variable crítica cuantitativa quality.
Al ver los diagramas de dispersión, ¿es plausible pensar que hay una relación entre las variables?
En nuestro conjunto de datos original todas las variables son contínuas. El cálculo de medidas de resumen bivariadas como las covarianzas o coeficientes de correlación, así como los resúmenes gráficos vistos, nos permiten tener una idea bien formada de si existen relaciones entre las variables y el sentido de dichas relaciones.
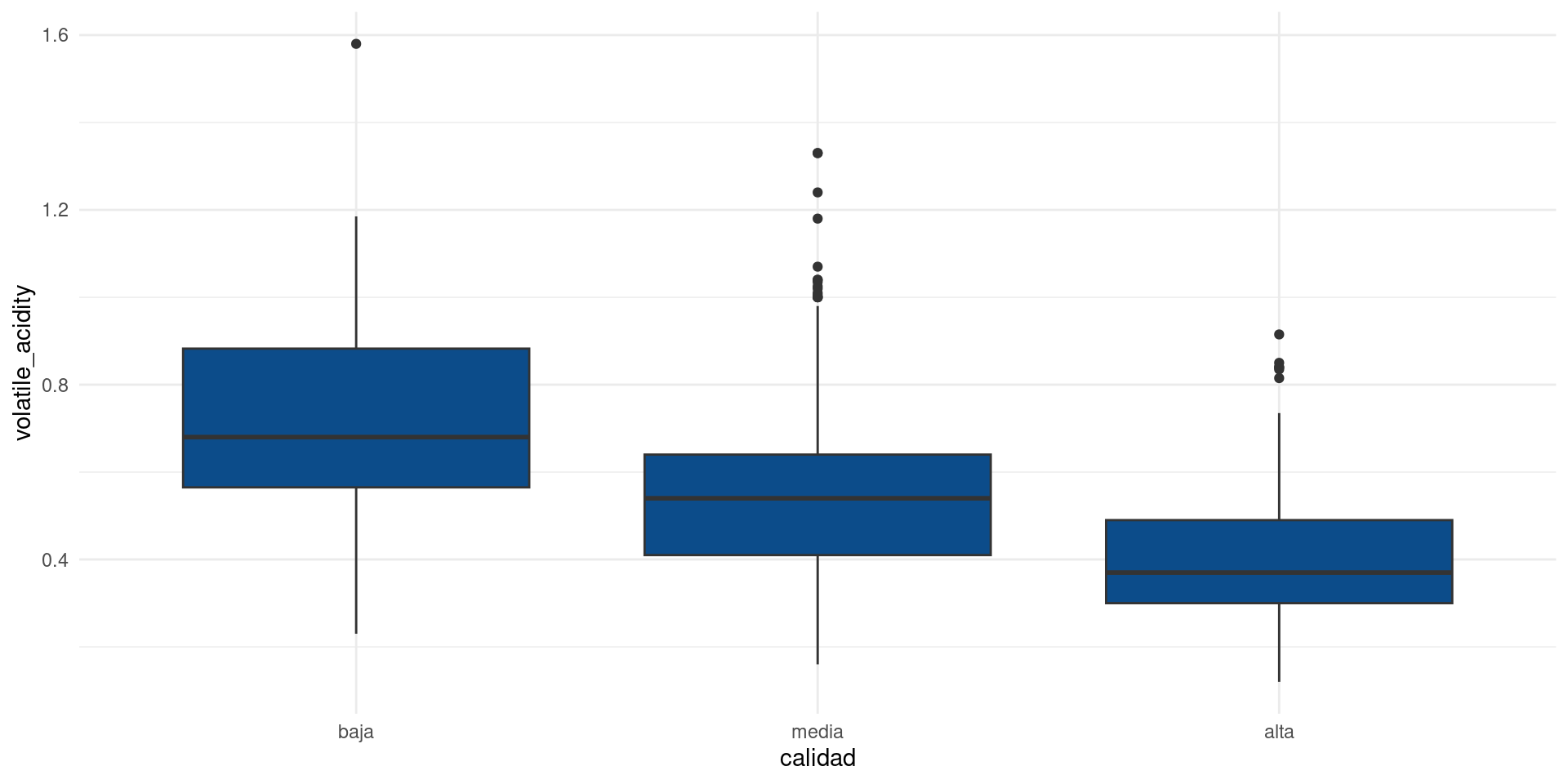
Escenario 2: Asociación entre una variable categórica y una variable contínua
En este escenario no podemos calcular covarianzas ni correlaciones de Pearson, luego debemos disponer de otro conjunto de herramientas para testear las relaciones entre las variables.
Correlación biserial-puntual
Regresión logística
Prueba de Kruskall-Wallis
Entre otras
Por facilidad, haremos una prueba de Kruskall-Wallis cuyo p-valor testeará la hipótesis de si existe una relación significante entre las variables.
Hipótesis nula: las variables son independientes.
Hipótesis alternativa: las variables no son independientes (puede existir un efecto causal).
# Damos nombre a las columnas y las filas colnames(tbl) <-c("Calidad baja", "Calidad media", "Calidad alta")rownames(tbl) <-c("Ácido acético bajo","Ácido acético alto")tbl
Calidad baja Calidad media Calidad alta
Ácido acético bajo 34 1122 210
Ácido acético alto 29 197 7
Al tener conformada la tabla de contingencia, la forma de revisar si existe una asociación entre las variables es por medio de una prueba de independencia X2 (Chi-Cuadrado).
La prueba indicará si dos características son independientes o tienen una asociación, de manera que las frecuencias elevadas en una de ellas suele ser acompañado con frecuencias altas en la otra.
Hipótesis nula: las columnas y las filas de la tabla son independientes.
Hipótesis alternativa: las columnas y las filas son dependientes (puede existir un efecto causal).
Identificar las relaciones existentes entre dos o más variables es parte arte y parte ciencia, por lo que se recomienda ganar experiencia leyendo articulos cientificos y viendo soluciones a diversos problemas.
Además,
Hay que procurar trabajar con variables informativas, es decir, que guarden una relación con la variable objetivo.
Hay que evitar las redundancias, luego lo ideal es que nuestras variables explicativas/independientes/features sean independientes entre sí.
Nuestra intuición puede fallar en dimensiones superiores a 3. En la mayoría de los casos aumentar la cantidad de variables afecta negativamente el entendimiento de un problema si no contamos con una gran cantidad de datos. Por ultimo, una cantidad controlada de variables asegura una mejor interpretabilidad de los análisis y modelos.