import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.colors
diamonds = sns.load_dataset(
"diamonds", cache=True, data_home=None
).sample(5000)
# You can uncomment this line to change the style of the graphs.
# plt.style.use('ggplot')Data-vis
Introducción a seaborn
Seaborn
Seaborn es una biblioteca de Python para la visualización de datos que está construida sobre Matplotlib. Está específicamente diseñada para crear gráficos estadísticos y tiene la ventaja de una integración estrecha con la biblioteca Pandas.
Antes de comenzar a crear gráficos con Seaborn, es importante tener una buena comprensión de la estructura de tus datos y asegurarte de que tu conjunto de datos esté preprocesado y listo para el análisis. Seaborn ofrece varias funciones y características, incluyendo:
Está orientada a trabajar con dataframes de Pandas, lo que te permite examinar las relaciones entre múltiples variables dentro de tu conjunto de datos.
Seaborn proporciona un fuerte soporte para manejar variables categóricas y visualizar observaciones y estadísticas agregadas.
Puedes usarla para visualizar distribuciones univariadas y bivariadas, facilitando la comprensión de las características de tus datos.
Ofrece características de estimación automática, como la creación de modelos de regresión lineal, simplificando la visualización de relaciones dentro de tus datos.
Puedes obtener información sobre la estructura general de los conjuntos de datos.
Seaborn proporciona abstracciones de alto nivel para crear arreglos en forma de cuadrícula de múltiples gráficos.
Puedes personalizar el estilo de tus visualizaciones con varios temas incorporados.
Incluye herramientas para seleccionar paletas de colores, haciendo que tus gráficos sean visualmente atractivos e informativos.
Funciones Gráficas Orientadas a lo Visual
Las fortalezas de Seaborn radican en sus funciones gráficas orientadas a lo visual, que te permiten crear gráficos visualmente atractivos que transmiten información de tus datos. Estas funciones están específicamente diseñadas para manejar diferentes tipos de datos y tareas de visualización. Vamos a explorar las funciones clave que mencionaste:
displot (abreviatura de “distribution plot”). Se utiliza para visualizar la distribución de una sola variable numérica. Con displot, puedes crear varios tipos de gráficos, como histogramas, estimaciones de densidad de kernel (KDE) y gráficos de función de distribución acumulativa empírica (ECDF). Esto te ayuda a comprender la forma, la dispersión y las tendencias centrales de tus datos.
relplot, abreviatura de “relationship plot”, se utiliza para visualizar la relación entre dos variables numéricas. Esta función puede generar gráficos de dispersión, gráficos de líneas y otras visualizaciones para mostrar cómo están relacionadas dos variables numéricas. Es especialmente útil para explorar patrones, correlaciones y tendencias en los datos.
catplot, o “categorical plot”, se utiliza principalmente para crear visualizaciones que involucren variables categóricas. Las variables categóricas representan diferentes categorías o grupos, y catplot puede generar varios tipos de gráficos como gráficos de barras, gráficos de cajas y gráficos de violín. Estos gráficos te ayudan a comprender la distribución y las relaciones dentro de tus datos categóricos.
jointplot se utiliza para la visualización bivariada. Te permite explorar la relación entre dos variables numéricas simultáneamente. Esta función crea un gráfico de dispersión de las dos variables junto con histogramas o estimaciones de densidad para cada variable en los márgenes. Esto facilita la comprensión de la distribución conjunta de las variables e identificar patrones, correlaciones o agrupaciones.
Cómo funciona
El uso básico de Seaborn es:
# Basic structure
sns.visualization-geometry(
data="Dataset",
x="X axis var",
y="Y axis var",
hue="Color var"
)
# Visual oriented function
sns.type-of.visualization(
data="Dataset",
x="X axis var",
y="Y axis var",
hue="Color var",
kind = "visualization-geometry",
col = "Column faceting var",
row = "Row faceting var"
)Further reading
Lee el tutorial de Datacamp
Lee la documentation de Seaborn
Visita The Python Graph Gallery para inspiración.
Basics
sns.scatterplot(x="carat", y = "price", data = diamonds) #oriented to data manipulation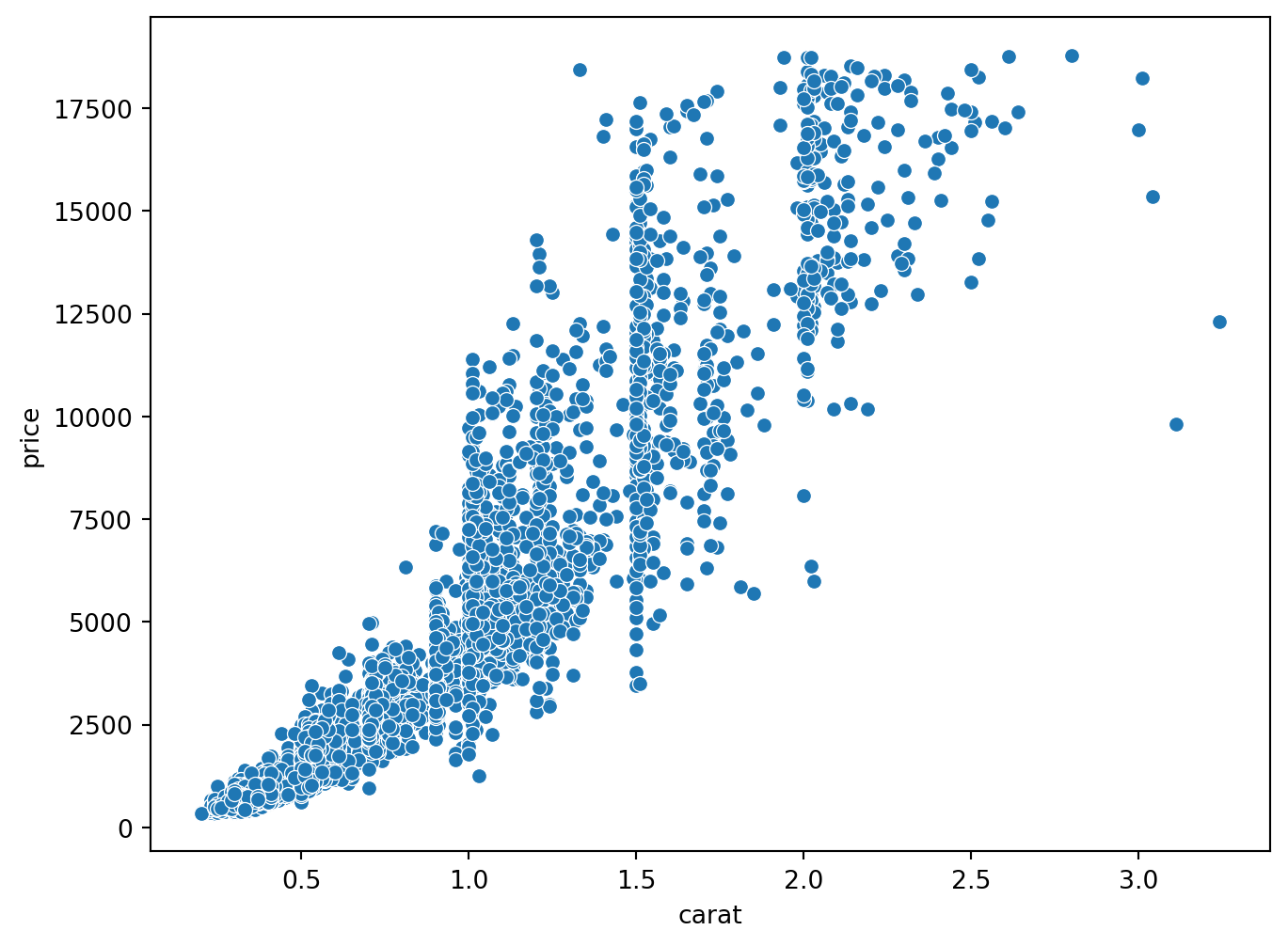
Count plot
sns.countplot(x = "cut", data = diamonds)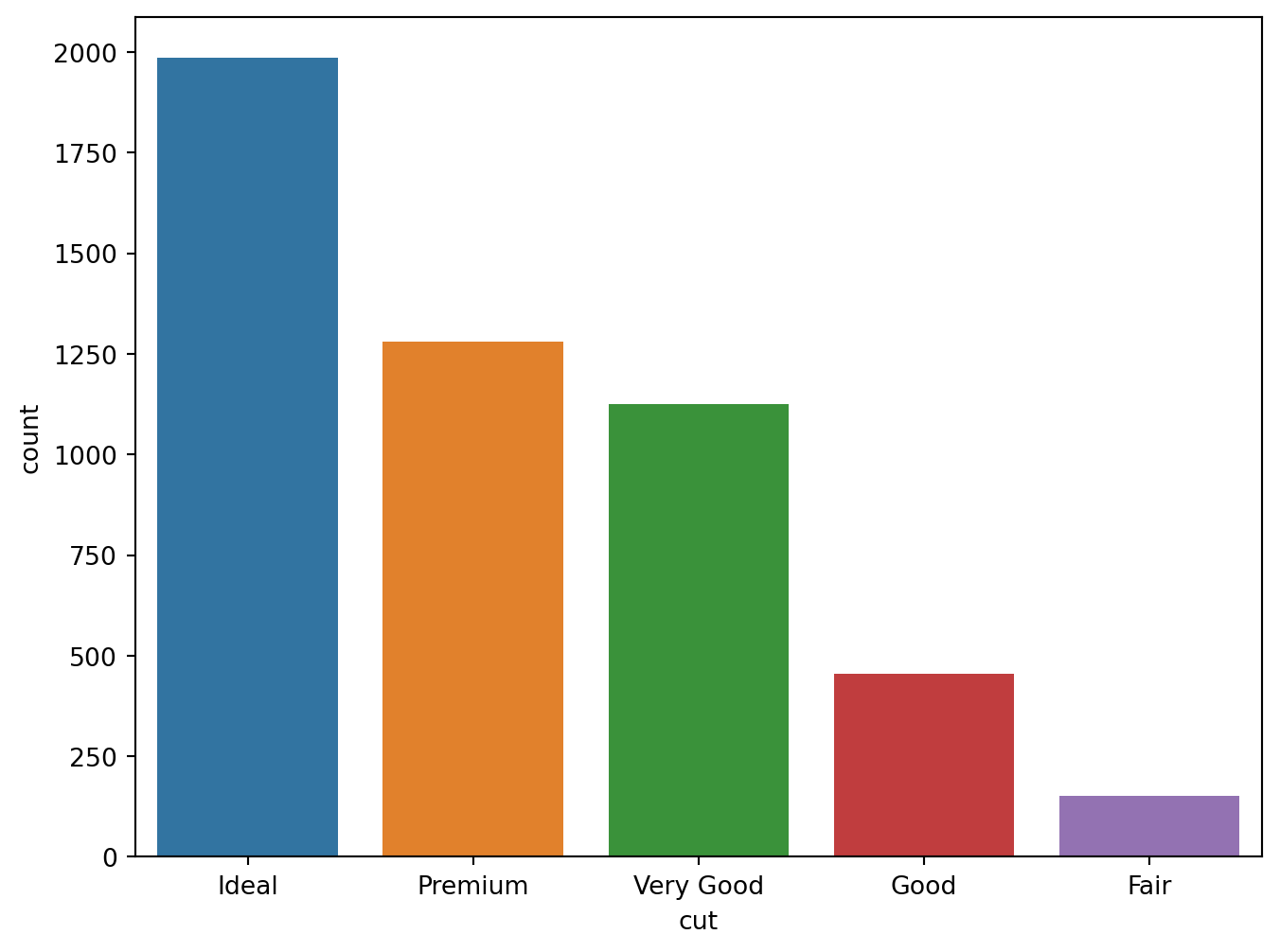
# sns.set(color_codes=True)
cut_percent = (diamonds["cut"]
.value_counts(normalize=True)
.rename('percent')
.reset_index())
sns.barplot(x="cut",y="percent", data = cut_percent)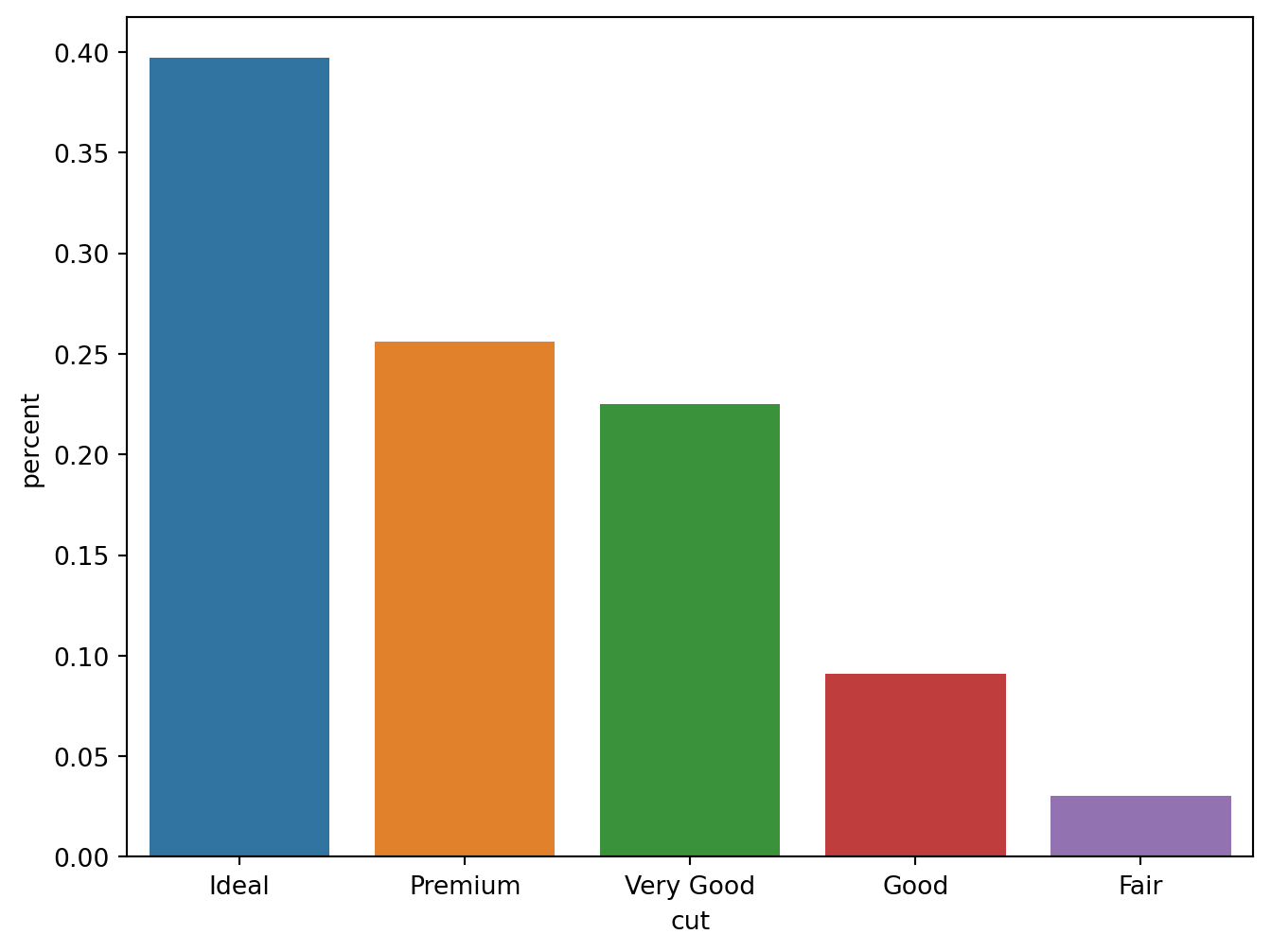
Histograma
sns.histplot(x = "price", data = diamonds)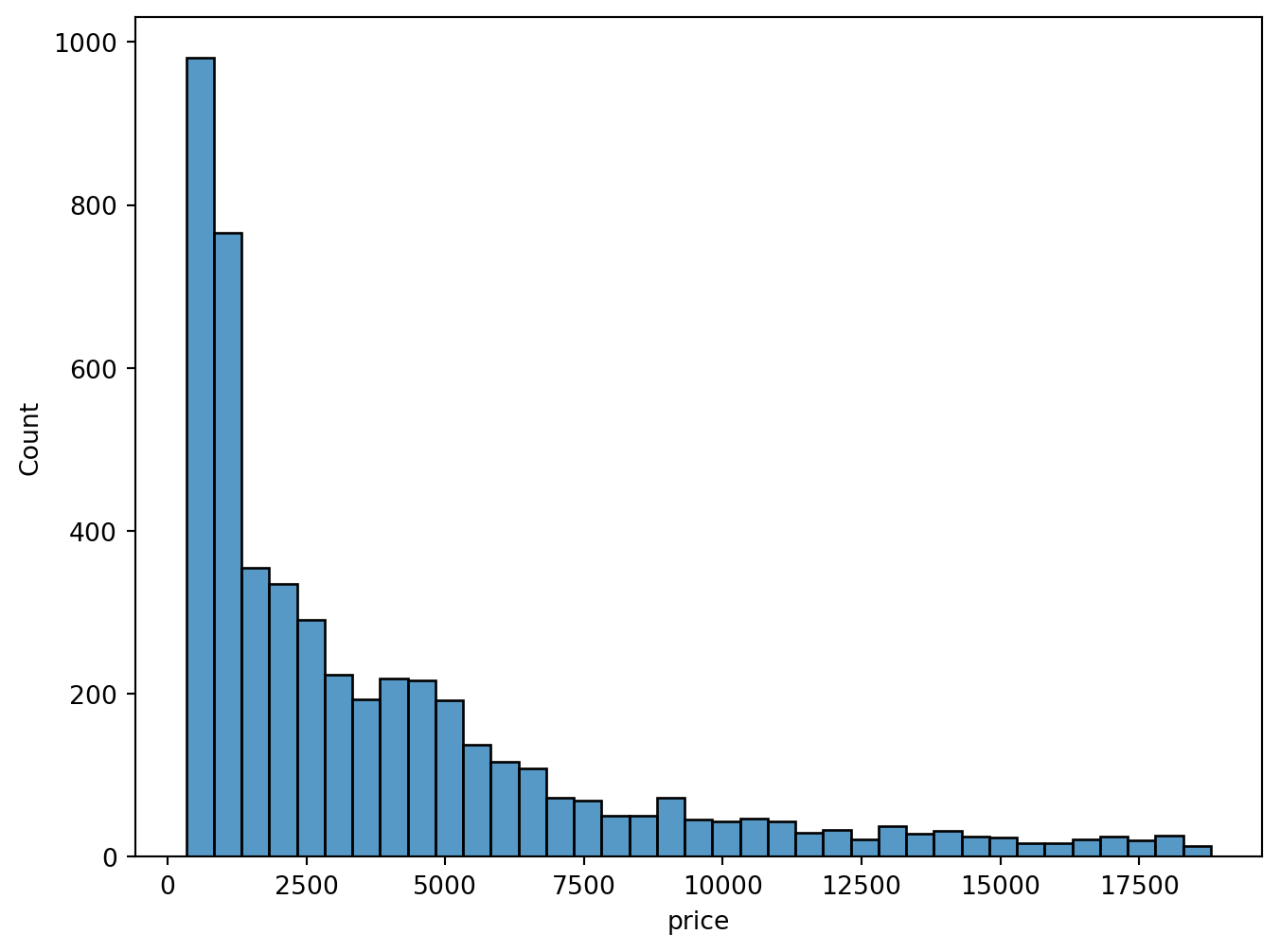
sns.histplot(x = "price", hue="color", data = diamonds)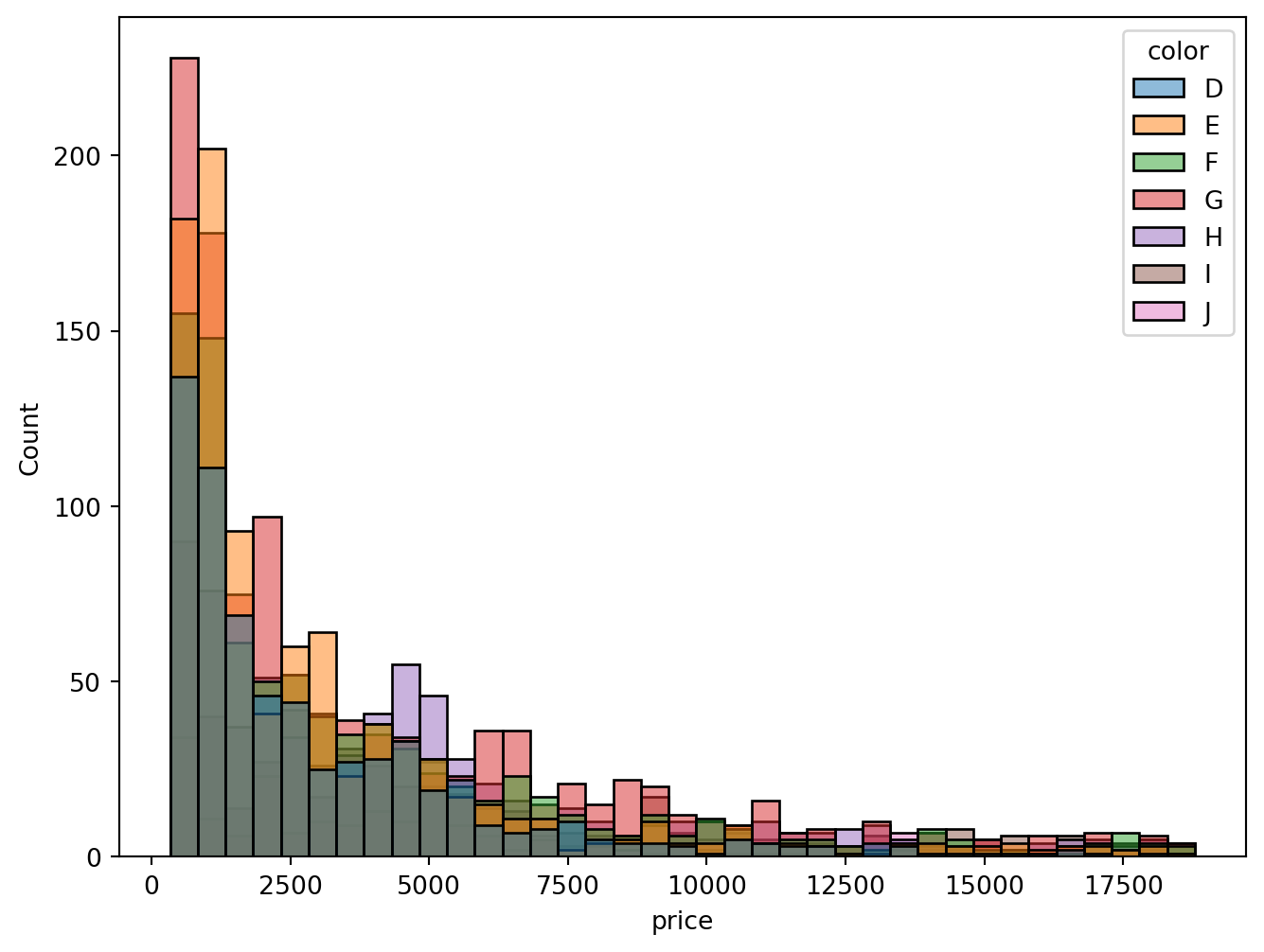
sns.histplot(x = "price", data = diamonds, stat="percent")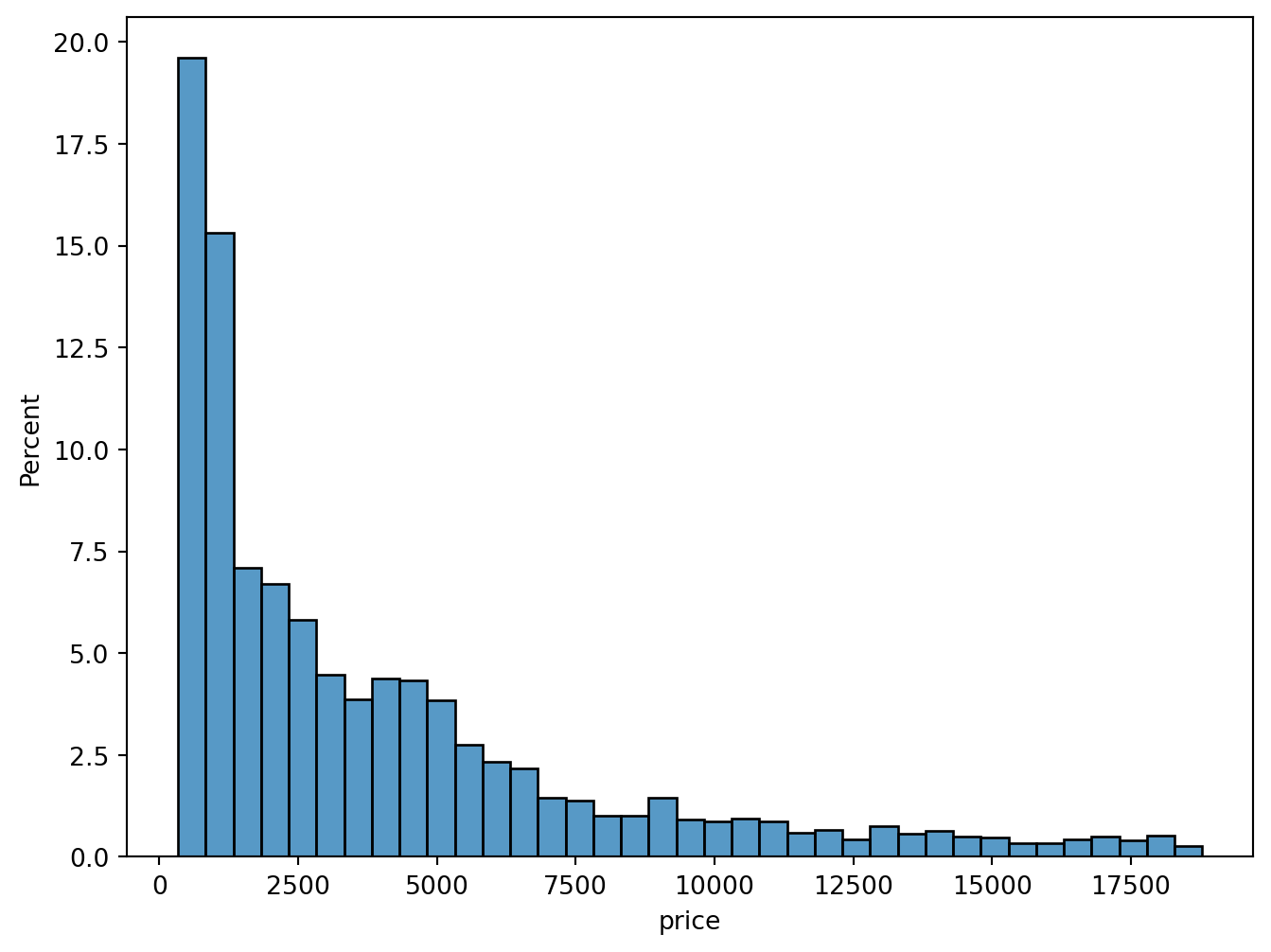
sns.histplot(x = "price", hue="color", data = diamonds, stat = "probability")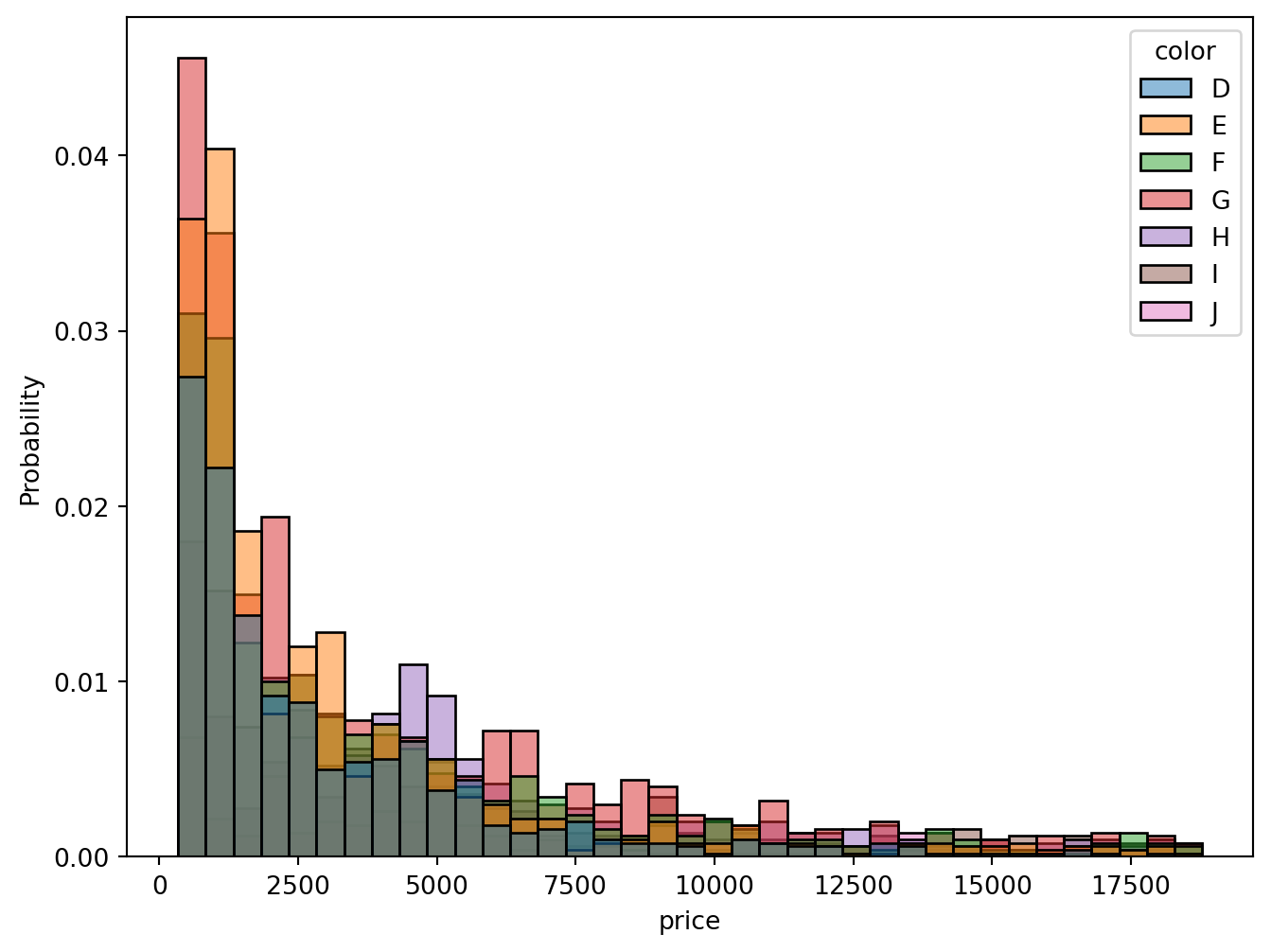
Estimador de densidad kernel
sns.kdeplot(x = "price", data = diamonds)
sns.kdeplot(x = "price", hue="color", data = diamonds)
ECDF plot
sns.ecdfplot(x = "price", data = diamonds)
sns.ecdfplot(x = "price", hue="color", data = diamonds)
Distribution plots
sns_gr = sns.displot(x = "price", data = diamonds, kind = "hist")
sns_gr = sns.displot(x = "price", data = diamonds, kind = "hist", row = "cut")
sns_gr = sns.displot(x = "price", data = diamonds, kind = "kde", col = "cut")
sns_gr = sns.displot(x = "price", hue = "color",data = diamonds, kind = "ecdf", col = "cut")
Scatterplot
sns.scatterplot(x="carat", y = "price", data = diamonds) 
sns.scatterplot(x="carat", y = "price", hue = "cut", data = diamonds) 
Line plot
x0 = np.linspace(0, 5, 11)
y0 = np.sin(x0)
sns.lineplot(x = x0, y = y0) 
Relational plot
sns_gr = sns.relplot(x = x0, y = y0, kind = "line") 
sns_gr = sns.relplot(x="carat", y = "price", data = diamonds, kind = "scatter") 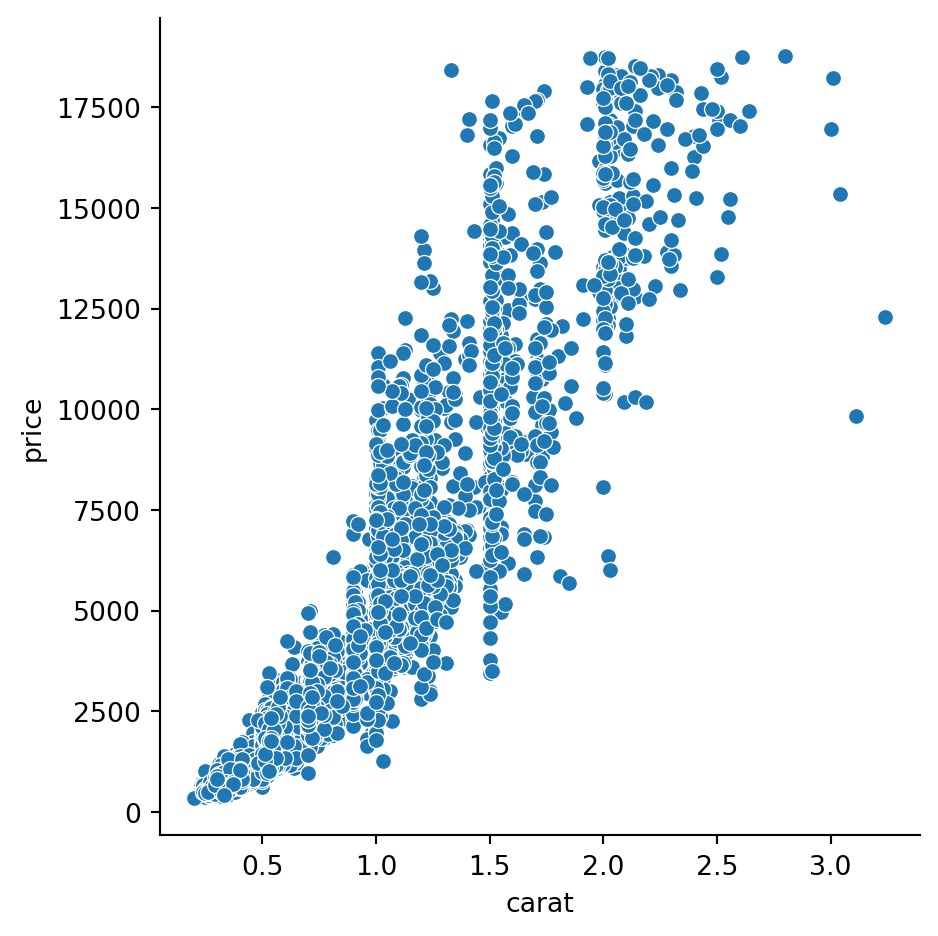
sns_gr = sns.relplot(
x="carat",
y = "price",
data = diamonds,
kind = "scatter",
row = "cut"
) 
sns_gr = sns.relplot(
x="carat",
y = "price",
data = diamonds,
kind = "scatter",
col = "color"
) 
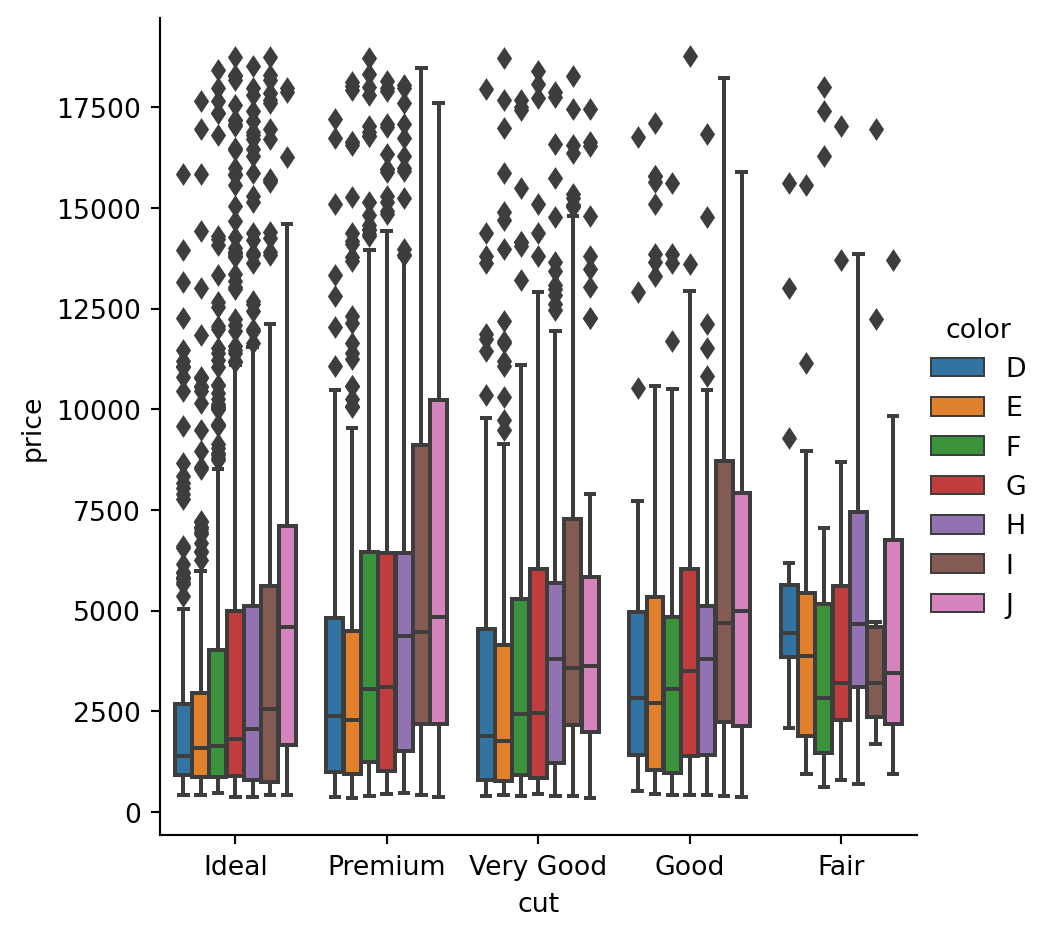
Cat plots
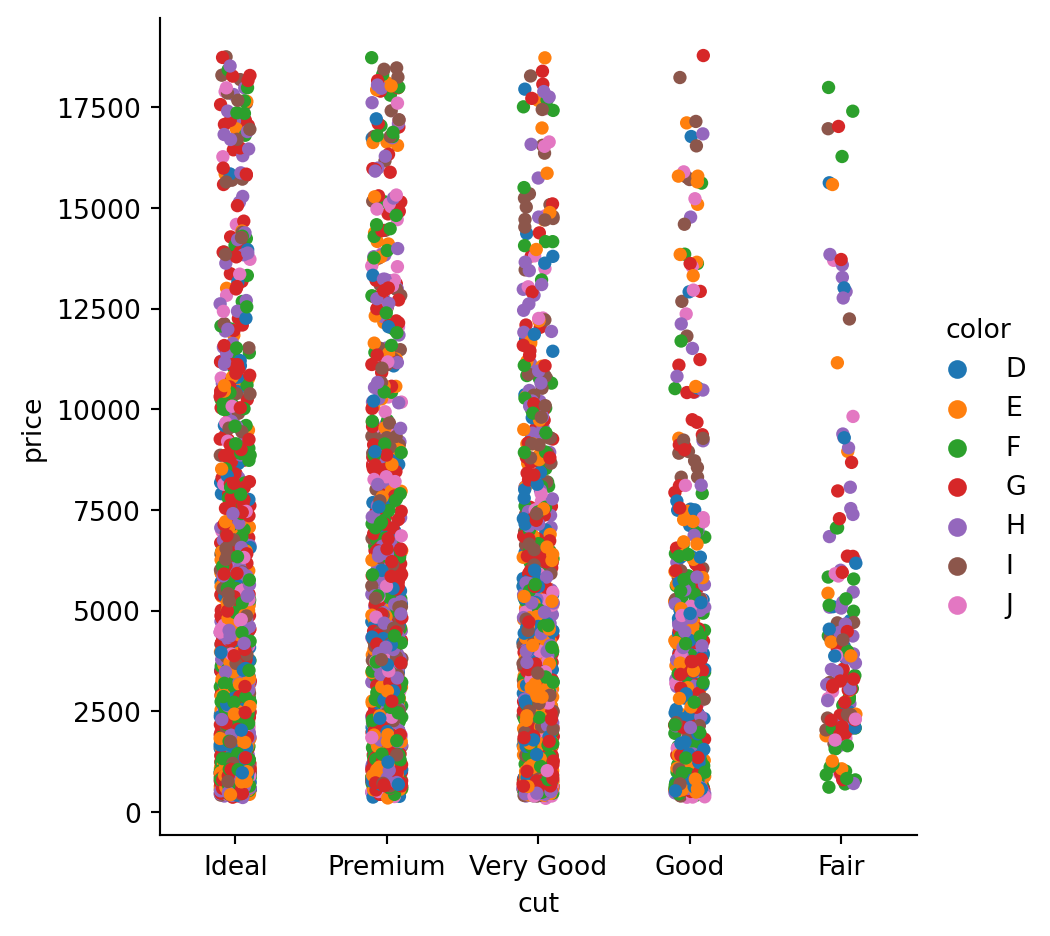
sns_gr = sns.catplot(
x="cut",
y = "price",
data = diamonds,
hue = "color"
) 
sns_gr = sns.catplot(
x="cut",
y = "price",
data = diamonds,
hue = "color",
dodge = True
) 
sns_gr = sns.catplot(
x="cut",
y = "price",
data = diamonds,
hue = "color",
kind = "bar",
dodge = True
) 
sns_gr = sns.catplot(
x="cut",
y = "price",
data = diamonds,
hue = "color",
kind = "violin",
dodge = True
) 
Joint plots
sns.jointplot(x="carat", y = "price", data = diamonds)
sns.jointplot(x="carat", y = "price", data = diamonds, kind = "kde")
sns.jointplot(x="carat", y = "price", data = diamonds, kind = "hist")
sns.jointplot(x="carat", y = "price", data = diamonds, kind = "reg")
sns.jointplot(x="carat", y = "price", hue = "color", data = diamonds)
Ejercicio
Genera las siguientes gráficas.